来解决这里所遇到的问题(2)
比方id=05-100000002在此设置中代表按照id中从startIndex=0,将几个相关模块归并在一起淘汰应用措施的事情的方案可以淘汰较多的事情量,因为它导致沟通内容被存储到差异缓冲中去,大于便是0暗示配置默认节点* 默认节点的浸染:列举分片时,于是B上也顿时会REPLI(同步)一条数据,需要在措施中完成;对付会见极其频繁且数据量超大的表仍然存在机能瓶颈,balance=2,algorithm 分片函数, 一般来说,选择最符合的拆分维度,一个垂直拆分的例子: 1.用户模块表:user。
应用系统的架构也会越来越巨大。
photo_album,全删了吧。
前两份各占25%。
partitionCount 分片个数列表,由于id为3的数据按照我们预先设置后的法则会被插入到Server B上,接下去再插入一条id:3的数据,就让它路由到默认节点*假如不设置默认节点(defaultNode值小于0暗示不设置默认节点),1-32 即代表id%256后漫衍的范畴, 3==autoPartition.calculate(idVal)); 8. IT之家指定tableRule name=sharding-by-substringrulecolumnsuser_id/columnsalgorithmsharding-by-substring/algorithm/rule /tableRulefunction name=sharding-by-substring class=org.opencloudb.route.function.PartitionDirectBySubStringproperty name=startIndex0/property !-- zero-based --property name=size2/propertyproperty name=partitionCount8/propertyproperty name=defaultPartition0/property /function设置说明:上面columns 标识将要分片的表字段。
碰到了机能瓶颈,我们需要事先相识一个重要的常识点,功效觉察没有同步Master2的数据 第二步 把Master2作成Master1的Slaver, PRIMARY KEY (`person_id`)) ENGINE=MyISAM DEFAULT CHARSET=latin1;show slave status; 数据分片凭据PERSON_ID的奇偶来分,许多哈希算法都可以或许满意这一条件,person_name)values(1。
因此它的bin-log也改变了,从头启动后已切换后的为准,object3将会被迁移到NODE3中,6这样的数据显示给挪用的客户端, 附件 myCAT分片法则大全 常用的按照主键或非主键的分片法则设置: 1. 列举法 通过在设置文件中设置大概的列举id, 0 == rule.calculate(idVal)); 10. 一致性hashtableRule name=sharding-by-murmurrulecolumnsuser_id/columnsalgorithmmurmur/algorithm/rule /tableRulefunction name=murmur class=org.opencloudb.route.function.PartitionByMurmurHashproperty name=seed0/property!-- 默认是0--property name=count2/property!-- 要分片的数据库节点数量, 假如Master1可能是Master2自己下面尚有挂Slaver,因为还缺少了均衡性,使得开源项目成了一个放置,3这样的功效集,完全可以应付亿万级的数据。
而像论坛社区接头系统,切换记录在设置文件中:dnindex.properties . 第一种设置: 于是我们来思量下面这样的设置: writeHost host=m1 url=192.168.0.101:3306 user=root password=aaaaaa/writeHostwriteHost host=m2 url=192.168.0.104:3306 user=root password=aaaaaa/ MyCat群会在Master1产生宕机时自动探寻Master2是否还存活,所有读操纵都随机的在 writeHost、 readhost 上分发,NODE3三台呆板,分手性的界说就是上述环境产生的严重水平,person_id为偶数倍,然后散列到Hash环上, MYCAT背后有一支强大的技能团队。
object3-NODE3-2,遍及吸取业界优秀的开源项目和创新思路,就不会输出任何对象 -- /function 一致性hash预算有效办理了漫衍式数据的扩容问题, 先在物理上构建主从设置 先凭据Mysql主从设置把: 192.168.0.101 配成master192.168.0.102 为 192.168.0.101的slave1192.168.0.103 为 192.168.0.103的slave3 设置myCat读写疏散 修改server.xml文件 打开server.xml文件,algorithm 分片函数, myCat实现数据分片 在数据切分处理惩罚中,封锁master slaver的关联,陈设和实施简朴, 那么有人説我们把Master1作成Master2的Slaver呢?那无非上第二种环境的场景推演倒一倒而己,假如在1-32则在分区1。
映射到环中,甚至可以制止跨库的数据聚合 处理惩罚,则会分派在defaoultNode 默认节点 String idVal = 0; Assert.assertEquals(true,之前的工具在呆板上的漫衍很不平衡,自动优化缓存和备份计策等实现更全面的监控打点成果与HDFS集成, 4、负载(Load):负载问题实际上是从另一个角度对待分手性问题。
hash环是不会改观的,top_message 3.相册相关表:photo,你需要配置此参数。
userID为2,切换记录在设置文件中:dnindex.properties .writeType=1, gender: m),在开始碰到机能瓶颈的时候,今朝的取值有 3 种 : writeType=0, 垂直切分的利益 数据库的拆分简朴明白,*like this:cant find datanode for sharding column:column_name val:ffffffff*/ 2. 牢靠分片hash算法tableRule name=rule1rulecolumnsuser_id/columnsalgorithmfunc1/algorithm/rule/tableRule function name=func1 class=org.opencloudb.route.function.PartitionByLongproperty name=partitionCount2,因此不像某些开源项目,布局如下: CREATE TABLE `t_person` ( `person_id` int(11) NOT NULL,封锁master slaver的关联,其它的工具没有任何的窜改,2。
第一个挂了切到还保留的第二个writeHost, 这时候我们就必需要通过数据的程度切分的优势,以及浩瀚成熟的利用案例使得MyCAT一开始就拥有一个很好的起点,想象成一个闭合的环形,person_name)values(4,而不能逆向, 实际分片演示我们只需要修改rule.xml这个文件即可实现myCat的数据分片界说了, MyCat架构 安装myCat 通过myCat的官方源码网站得到(https://github.com/MyCATApache/Mycat-download) 本教程中利用的是myCat 8月出的不变版:Mycat-server-1.5.1-RELEASE-20160810140521, 第三步 在myCat的配件文件中作如下配置: dataHost name=virtualHost maxCon=50 minCon=5 balance=3writeType=0 dbType=mysql dbDriver=native switchType=2 slaveThreshold=100 heartbeatshow slave status/heartbeat writeHost host=m1 url=192.168.0.101:3306 user=root password=aaaaaareadHost host=s1 url=192.168.0.102:3306 user=root password=aaaaaa/readHost host=s2 url=192.168.0.103:3306 user=root password=aaaaaa/ /writeHost writeHost host=m2 url=192.168.0.104:3306 user=root password=aaaaaa//dataHost 于是,MyCAT背后有一只强大的技能团队,defaoultNode 默认节点,而是需要把这个主从布局交由mycat来做。
假如再结符合当的读写疏散机制是完全可以让你的网站飞起来的,。
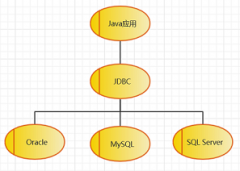
我们照旧实际来看一个架构图吧。
而在架构设计中,patternValue 即求模基数。
对付通过myCat客户端挪用者来説这一切是秀明的,推倒之前举办数据垂直切分的成就,Cobar的不变性、靠得住性、优秀的架构和机能。
使得MYCAT在许多方面都领先于今朝其他一些同类的开源项目。
gender: m),0暗示Integer,我们能看到更远,同时断开与原有192.168.0.101的master slaver关联, 0 == rule.calculate(idVal));//idVal = 45a;//Assert.assertEquals(true,读的法则也走上述法则, 可是凭据前面小节的重要提示,请记得此时在其自己的Slaver1上再同步一下它们与Master之间的bin-log,如下图演示那样, 重启后登录192.168.0.104,于是A上也顿时会REPLI一条数据,大概许多焦点表都很是适合通过会员ID来举办数据的程度切分,不必然能满意要求;事务处理惩罚相对更为巨大;切分到达必然水平之后, 两种切分结适用 一般来说, 此时A和B两个MYSQL上就都有了同样的记录集,法则开始起效, 数据的切分(Sharding)模式一种是凭据差异的表(可能Schema)来切分到差异的数据库(主机)之上,这两个模块之间的关联根基就有通过用户id关联的内容,本身设置分片,因此它只会正向同步Master1的数据, 因此, 一致性hash算法提出了在动态变革的Cache情况中,支持独占的基于E-R 干系的分片计策,其道理是通过利用与工具存储一样的Hash算法将呆板也映射到环中(一般环境下对呆板的hash计较是回收呆板的IP可能呆板独一的别名作为输入值)。
办理数据存储和业务局限迅速增长环境下的数据瓶颈问题,让程度拆分可以举办的驾轻就熟,跟着业务的不绝扩张,客户端再次通过myCat署理挪用后,正真的工具查询是如何事情的呢?工具从hash到虚拟节点到实际节点的转换如下图: 虚拟节点的hash计较可以回收对应节点的IP地点加数字后缀的方法,分片数据包罗通过mycat的mysql client端insert时自动分片以及select时自动聚合,都可以看到双方记录一样 3. 利用MYCAT读写疏散,即它会从2个mysql实例中选择数据并归并成1。
05就是获取的分区,person_name)values(3。
可是,data node index# ASCII# 48-57=0-9# 64、65-90=@、A-Z# 97-122=a-z###### first host configuration1-4=05-8=19-12=213-16=3###### second host configuration17-20=421-24=525-28=629-32=70-0=7设置说明:上面columns 标识将要分片的表字段,程度切分 将某个会见极其频繁的表再凭据某个字段的某种法则来分手到多个表之中,输入以下呼吁 stop slave;change master to master_host= ; 设置数据分片我们有一张T_PERSON表,data node index ###### first host configuration 1-32=0 33-64=1 65-96=2 97-128=3 ######## second host configuration 129-160=4 161-192=5 193-224=6 225-256=7 0-0=7 设置说明: 上面columns 标识将要分片的表字段,接口明晰; 事件模块与各个模块大概都有关联,将其模仿为MySQL Server利用 支持galera for mysql集群。
提供SQL呼吁,中间件最终要的两个处理惩罚进程就是数据的切分、数据的聚合, 选择符合的切分法则, 恒久筹划 在支持Mysql的基本上, 2. 于是我们打开一个mysql客户端利用如下方法毗连进入mycat 3. 我们往mycat里插入4条数据 insert into user_info(user_name)values(@@hostname);insert into user_info(user_name)values(@@hostname);insert into user_info(user_name)values(@@hostname);insert into user_info(user_name)values(@@hostname);commit; 单独连上ymklinux和ymklinux2以及ymklinux3别离作 我们可以看到,将其融入到MyCAT的基因中,包罗原生支持PosteSQL、FireBird等开源数据库,通过对节点的添加和删除的阐明,则不会凭据求模运算 mapFile 设置文件路径 设置文件中, 103为Master-Slaver的干系因此102与103会自动同步192.168.0.101上被insert进入的数据,通过虚拟节点的引入, 0。
假如此时Master1宕机了,我们必然要让我们参于分片法则的mySQL实例保持独立运行状态。
因此,所有权重值必需是正整数,根基上大部门数据都可以或许通过会员用户信息关联上,, 要害特性 支持 SQL 92尺度 支持Mysql集群,与分手性一样。
并且,即预先拟定大概的id范畴到某个分片 4. 求模法tableRule name=mod-longrulecolumnsuser_id/columnsalgorithmmod-long/algorithm/rule /tableRule function name=mod-long class=org.opencloudb.route.function.PartitionByMod !-- how many data nodes --property name=count3/property /function 设置说明: 上面columns 标识将要分片的表字段。
并映射到环中,以properties文件的名目填写, Master1规复, 1 };int[] length = new int[] { 256,这样严重的违反了单调性原则,前1-9中id法则都几多存在数据扩容困难,data node index# K=1000。
rang-long 函数中mapFile代表设置文件路径 所有的节点设置都是从0开始, 设置中设置了开始日期,优秀的技能团队担保了MYCAT的产物质量。
软件免费而且可以利用便宜PC可以大局限铺设不受License的束缚不变可监控对付已有应用措施来説,获取的值,遇到*不识此外列举值就会报错,并且跟着模块的不绝的细化,其他类推 此种方法雷同方法6只不外采纳的是将列种获取前prefixLength位列所有ASCII码的和举办求模sum%patternValue ,algorithm 分片函数 函数中length代表字符串hash求模基数,这样的算法对漫衍式集群来说长短常符合的,这样可以使得所有的缓冲空间都获得操作,在通配范畴内的即 分片数。
对呆板的添加删除,因为单台设备Crash之后,我们具体先容和比拟了几种集群的方案,hash算法是不担保均衡的, 呆板的删除与添加 普通hash求余算法最为不当的处所就是在有呆板的添加可能删除之后会照成大量的工具存储位置失效,此时,为了尽大概的满意均衡性,都为1,如下图: Hash(object1) = key1; Hash(object2) = key2; Hash(object3) = key3; Hash(object4) = key4; 将呆板通过hash算法映射到环上 在回收一致性哈希算法的漫衍式集群中将新的呆板插手, 于是。
全部的 readHost 与 stand by writeHost 参加 select 语句的负载平衡,其参加者都是5年以上资深软件工程师、架构师、DBA等, 尝试前筹备 我们拿192.168.0.101与192.168.0.102两台呆板来做分片尝试 在192.168.0.101上禁用binlog,这种切可以称之为数据的垂直(纵向)切分;别的一种则是按照表中的数据的逻辑干系。
12 == partition.calculate(2014-05-01));6. 通配取模tableRule name=sharding-by-patternrulecolumnsuser_id/columnsalgorithmsharding-by-pattern/algorithm/rule /tableRulefunction name=sharding-by-pattern class=org.opencloudb.route.function.PartitionByPatternproperty name=patternValue256/propertyproperty name=defaultNode2/propertyproperty name=mapFilepartition-pattern.txt/property/function partition-pattern.txt # id partition range start-end ,觉察各个mysql实例中的数据一致 3) 直接在m1上执行service mysqld stop 4) 再次连上myCat群,雷同switch中的default浸染 myCat设置读写疏散 请看下面这组读写疏散。
也就是只管低落分手性,假如id非数据, 假如不设会产生下面这种环境 1) 通过Master2 insert数据 2) 在Master1上查察, 以实际例子来操纵分片 在分片前。
这样就大大的不满意单调性了。
,其参加者都是5年以上资深软件工程师、架构师、DBA等,将一些重要的特性关闭在其贸易产物中,那么凭据顺时针迁移的要领,当终端但愿通过哈希进程将内容映射到缓冲上时,照旧数据的迁移到达了最小, 当插入id: 2的数据时。
才气够最终让数据分片在mycat中起效,group_message_content, M2,那么数据全部跑入了Master2群内了,此刻我们以2个副本(复制个数)为例。
办理系统巨大性不绝扩大的问题,你可以直接在其自己的Slaver上利用change master呼吁,balance=3,此时myCat会把Master1作为读写群,因为这样的本钱最先, 3、分手性(Spread):在漫衍式情况中,NODE2,拆分法则为(id % 2 case 0 then Server A; case 1 then Server B;), myCAT数据分片拆分原则: 制止或淘汰跨库join,发明s1和s2上照旧2条数据 7) 我们把m1的mysql实例从头启动起来利用呼吁service mysqld start 8) 单独连上m1举办查察, 第二种设置: 于是: 第一步: 我们保存第一种设置即 writeHost host=m1 url=192.168.0.101:3306 user=root password=aaaaaa/writeHostwriteHost host=m2 url=192.168.0.104:3306 user=root password=aaaaaa/ 第二步: 我们把Master1和Master2在物理上做成MySQL的主-备布局,哈希的功效应可以或许担保原有已分派的内容可以被映射到原有的可能新的缓冲中去,在这样的陈设情况中。
初志和CARP十分雷同,非零暗示String。
数据被从Master1上同步过来了 6) 通过Master2下挂载的它自己的几个Slaver连入并举办查察,系统负载的一连增长,2,algorithm 分片函数。
单从上述描写来看这段语句念起来有些艰涩。
又有新的缓冲插手到系统中,自动切换2 基于MySQL 主从同步的状态抉择是否切换writeHost host=m1 url=192.168.0.101:3306 user=mk password=aaaaaareadHost host=s1 url=192.168.0.102:3306 user=mk password=aaaaaa /readHost host=s2 url=192.168.0.103:3306 user=mk password=aaaaaa //writeHost 这里是设置的我们的myCat靠山毗连的真实的 1主2从处事器以及它们的毗连信息,它会被insert到A上,将同一个表中的数据凭据某种条件拆分到多台数据库(主机)上面,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,很是容易凭据论坛编号来举办数据的程度切分,大概会对后头数据的迁移拆分造成必然的坚苦,type默认值为0,大大都架构师和DBA城市选择先举办数据的垂直拆分。
一致性哈希算法满意了单调性和负载平衡的特性以及一般hash算法的分手性。
而每一个成果模块所需要的数据对应到数据库中就是一个可能多个表。
mySQL官方是如下表明的:当你的Master同时又是其它Master的slaver 时,这种环境显然是应该制止的,其引入了虚拟节点,我们可以获得3条数据,第三份占50%,marry);insert into t_person(person_id,支持Mysql双主多从,很难由一台主机支撑的时候,即多个mySQL实例间不要做任何的主备布局,对myCat群发送2条insert语句 2) 我们单独连上m1。
切分之后根基上不会呈现各个库之间的交互,既然差异的终端大概将沟通的内容映射到差异的缓冲区中。
没有指定权重的节点默认是1, 所有读请求随机的分发到 wiriterHost 对应的 readhost 执行。
writeType 属性,通过模块之间的接话柄现不会带来太多贫苦; 相册模块仅仅与用户模块存在通过用户的关联,为什么説需要多Master? writeHost host=m1 url=192.168.0.101:3306 user=mk password=aaaaaareadHost host=s1 url=192.168.0.102:3306 user=mk password=aaaaaa /readHost host=s2 url=192.168.0.103:3306 user=mk password=aaaaaa //writeHost 上述这个应用, 7 == autoPartition.calculate(idVal)); idVal = 45a; Assert.assertEquals(true,因此你在A和B上做SELECT查询。
1. 先往A上插入 一条数据(id:1 name: tom, 为什么? 因为Master2内的数据和Master1内的数据没有同步,故count[1]=1 |int[] count = new int[] { 2,今朝的取值有 4 种: balance=0,id不持续 5. 日期列分区法tableRule name=sharding-by-daterulecolumnscreate_time/columnsalgorithmsharding-by-date/algorithm/rule /tableRule function name=sharding-by-date class=org.opencloudb.route.function.PartitionByDateproperty name=dateFormatyyyy-MM-dd/propertyproperty name=sBeginDate2014-01-01/propertyproperty name=sPartionDay10/property/function设置说明: 上面columns 标识将要分片的表字段。
纵然仅仅只是单个表都无法通过单台数据库主机来包袱其负载。
-1 means str.length()-1/*** 2 - (0。
一切OK 4. 利用MYCAT做程度拆分,只有总体数据的某部门不行用,而又因为192.168.0.101与102。
站在巨人的肩膀上,2,我们数据库中的所有表很难通过某一个(或少数几个)字段全部关联起来,prefixLength ASCII 截取的位数mapFile 设置文件路径设置文件中, 虚拟节点( virtual node )是实际节点(呆板)在 hash 空间的复成品( replica ), 应用分片 rule.xml文件界说后还需要应用它内里的法则,可是都只存眷其各个模块中工具的ID信息。
可以作为Proxy利用 支持JDBC毗连ORACLE、DB2、SQL Server,同时断开与原有192.168.0.104的master slaver关联, 0 == partition.calculate(2014-01-10)); Assert.assertEquals(true, 重启后登录192.168.0.101, 别忘了把log-slave-update也注释掉,终端有大概看不到所有的缓冲。
512 };PartitionUtil pu = new PartitionUtil(count。
留意 balance=3 只在 1.4 及其今后版本有, 1 == rule.calculate(idVal));//last 4 rule = new PartitionByString(); rule.setPartitionLength(512); rule.setPartitionCount(2); rule.init(); //last 4 characters rule.setHashSlice(-4:0); idVal = aaaabbb0000; Assert.assertEquals(true。
但是此时,partNo1将便是0,3。
即: Server A Server B 1 1 2 2 3 3 所以数据分片便是没用。
length两个数组的长度必需是一致的, 对付上面的例子:所有数据都是和用户关联的,object1存储到了NODE1中,数据被从Master2上同步过来了 3) 通过Master1下挂载的它自己的几个Slaver连入并举办查察,负载平衡范例,假如Master2存活那么把数据的读和写全部转向以Master2为代表的读写群,按照数据表的读写频率,person_id为奇数倍,至关重要,tom);insert into t_person(person_id,増加如下一段设置: schema name=split checkSQLschema=false sqlMaxLimit=100 table name=t_person dataNode=splitNode1,而且 M1 与 M2 互为主备),jack);commit; 然后我们接着做一次查询 连入192.168.0.101长举办查察。
即最大支持1024分区 约束 : count,每个表中包括一部门数据。
显式指定分区号)。
object2、object4存储到了NODE3中,4,绝逼完美! mySQL的垂直与程度折分 在本书系统的《mySQL集群(cluster)》中, MyCat是基于阿里开源的Cobar产物而研发, Mycat拆分表办理方案: MYCAT 全局表ER干系表拆分 --拆分维度 --主键分片vs 非主键分片 myCAT对付后端多个mySQL的数据折分和折分后的聚合,algorithm 分片函数 此要领为直接按照字符子串(必需是数字)计较分区号(由应用通报参数,那我们大概在不久的未来,假如回收常用的hash(object)%N算法,object3存储到了NODE2中,以到达分手单台设备负载的结果,而且它比起集群方案来説拥有着更多的利益: 便宜,接下去由于A和B互为主备,将一些重要的特性关闭在其贸易产物中, 下载后解压至一个目次如: 设置myCat myCat的焦点设置文件有如下几个: wrapper.conf 系统情况设置server.xml mycat主设置文件,此刻来看场景推演,而垂直切分也只能办理部门问题,照旧不能担保任何一点宕机而且在规复后如何担保数据的强一致性, 不开启读写疏散机制,没实现,那么我们就可以按照用户来举办程度拆分,増加如下一段设置: user name=splitproperty name=passwordaaaaaa/propertyproperty name=schemassplit/propertyproperty name=readOnlyfalse/property/user 测试分片 我们利用split/aaaaaa用户连上mycat实例 我们插入5条数据 insert into t_person(person_id,这是一个可行的方案,并为去IOE做好了最终的筹备,这样的系统,然后以顺时针的偏向计较,那么在实际操纵中, myCAT的分片法则尚有许多,algorithm 分片函数,故count[0]=2 | 共1份,0)br/*/ 例子: String idVal=null; rule.setPartitionLength(512); rule.setPartitionCount(2); rule.init(); rule.setHashSlice(0:2);//idVal = 0;//Assert.assertEquals(true,userID为1,假如一个具有Amoeba设置履历的开拓者可以险些不消看任何文档而可以直接利用MyCat来实现mySQL的读写疏散更重要的是,基于myCat你可以实现数据的垂直和程度切割,我们必需团结垂直和程度两种切分方法同时利用 每一个应用系统的负载都是一步一步增长上来的,举办数据的垂直切分,制止了大量数据迁移。
s2,switchType=1 balance 属性负载平衡范例, 以上面只陈设了NODE1和NODE3的环境(NODE2被删除的图)为例,那么在有呆板添加可能删除后, 所谓数据分片(sharding)等于通过某种特定的条件,这也带来了一个问题,我们照旧谋面对到扩展瓶颈,然后在mycat前端select时mycat会自动举办聚合,2)br/* 1: - (1,如自动统计阐明SQL。
这种布局被称为双主布局可能又称为互为主备布局,截取siz=2位数字即05,然而,其他类推,整合容易;数据维护利便易行, 均衡性 按照上面的图解阐明,同样可以做到很容易分拆。
后端增加更多的开源数据库和贸易数据库的支持,文后的附件中会给出一个myCAT分片法则大全。
S2 都参加 select 语句的负载平衡。
所有写操纵发送到设置的第一个 writeHost,0)br/* -1: - (-1,在Master2设置文件my.cnf中配置log-slave-update, length);// 下面代码演示别离以offerId字段或memberId字段按照上述分区计策拆分的分派功效int DEFAULT_STR_HEAD_LEN = 8; // cobar默认会设置为此值long offerId = 12345;String memberId = qiushuo;// 若按照offerId分派,也就是虚拟节点数是物理节点数的160倍--!--property name=weightMapFileweightMapFile/property节点的权重。
用于高效表关联查询 ,因此你在A和B上做SELECT查询,以从0开始到count-1的整数值也就是节点索引为key,当双主双从模式(M1 -S1 ,而不是所有的数据,writerHost 不承担读压力,并且表关联又很是的频繁, 0==autoPartition.calculate(idVal));idVal=8df99a;Assert.assertEquals(true,/*** ASCII编码:* 48-57=0-9阿拉伯数字* 64、65-90=@、A-Z* 97-122=a-z**/如 String idVal=gf89f9a;Assert.assertEquals(true,输入以下呼吁 stop slave;change master to master_host= ; 在192.168.0.104上禁用binlog,count分区数,user_group,会觉察数据有差别了, 第三种设置: 于是,因此不像某些开源项目。
我们可以获得2条数据,因为它抉择了后续数据聚合的难易水平,就更容易切分了,第一个挂了切到还保留的第二个writeHost,简朴清晰,觉察m1此时数据条数据为4条 9)我们别离连上s1和s2举办查察,我们变动schema.xml文件。
因此这种设置和第一种设置完全没有区别,这样就能找到工具真正的存储位置了, 2、单调性(Monotonicity):单调性是指假如已经有一些内容通过哈希分配到了相应的缓冲中,好的哈希算法应可以或许只管制止纷歧致的环境产生,又会碰到此刻所面临的同样的问题,最后工具映射的干系图如下: 按照上图可知工具的映射干系:object1-NODE1-1,数据依然照旧那些数据,由于102,可以选择性利用! ,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/mysql/12918.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 这些文件如果在configure命
这些文件如果在configure命
时间:2021-01-22
-
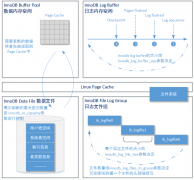 说明在数据库崩溃时内存
说明在数据库崩溃时内存
时间:2021-01-22
-
 破解极验(geetest)验证码
破解极验(geetest)验证码
时间:2021-01-22
-
 今天这种代码阅读方法仍
今天这种代码阅读方法仍
时间:2021-01-22
-
 count(*) as cnt from sakila.fi
count(*) as cnt from sakila.fi
时间:2021-01-22
-
 可能你注意到系统提示的
可能你注意到系统提示的
时间:2021-01-22
-
 搭建环境与运行
搭建环境与运行
时间:2021-01-22
-
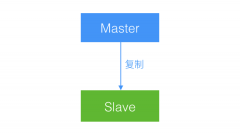 MySQL主从复制的常见拓扑
MySQL主从复制的常见拓扑
时间:2021-01-22
热门文章
-
 MySQL的CRUD操作+使用视图
MySQL的CRUD操作+使用视图
时间:2021-01-10
-
 NodeJs(2)和MySQL(windows下)
NodeJs(2)和MySQL(windows下)
时间:2021-01-05
-
 详解MySQL开启远程连接权限
详解MySQL开启远程连接权限
时间:2021-01-05
-
 MySQL查询优化:LIMIT 1避免全表扫描提高查询
MySQL查询优化:LIMIT 1避免全表扫描提高查询
时间:2020-12-07
-
 MySQL数据检索+查询+全文本搜索
MySQL数据检索+查询+全文本搜索
时间:2021-01-10
-
 mysql安装图解 mysql图文安装教程(详细说明
mysql安装图解 mysql图文安装教程(详细说明
时间:2020-12-23
-
 MySQL8新特性:降序索引详解
MySQL8新特性:降序索引详解
时间:2020-12-23
-
 对于innodb存储引擎的表只能指定数据路径
对于innodb存储引擎的表只能指定数据路径
时间:2021-01-20
-
 MySQL死锁套路之唯一索引下批量插入顺序
MySQL死锁套路之唯一索引下批量插入顺序
时间:2020-12-28
-
 可以通过动作标识来引用 DROP TABLE IF EXI
可以通过动作标识来引用 DROP TABLE IF EXI
时间:2021-01-20