[MySQL Reference Manual] 20 分区
mysql> SHOW PLUGINS;
+------------+----------+----------------+---------+---------+
| Name | Status | Type | Library | License |
+------------+----------+----------------+---------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ARCHIVE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| BLACKHOLE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
| FEDERATED | DISABLED | STORAGE ENGINE | NULL | GPL |
| MEMORY | ACTIVE | STORAGE ENGINE | NULL | GPL |
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MRG_MYISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MyISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ndbcluster | DISABLED | STORAGE ENGINE | NULL | GPL |
+------------+----------+----------------+---------+---------+
11 rows in set (0.00 sec)
也可以检查information_schema.plugins表检查是否支持。
如果partition的status不是active,或者没有记录。那么就不支持分区。
如果编译的时候已经支持了分区,就不需要去启动。如果想要不支持分区,可以使用参数—skip-partition选项。不启动分区后,不能看到已经分区的表,也不能删除他们。
20.1 MySQL的分区概述SQL标准一般不会涉及到关于数据存放物理方面。SQL语言本身尽量从数据结构,schema,表,行,列中独立出来。但是很多高级的数据库管理系统都涉及了某些数据存放的物理位置,文件系统,硬件等。在MySQL,InnoDB存储引擎,支持表空间已经很久,MySQL服务可以把不同的数据库存放到不同的物理目录中。
分区者更进了一步,把一个表根据规则分布到文件系统。实际上表的不同分区以独立表的方式被保存在不同的位置上。用户选择的分区规则,在MySQL中可以是一个模块,一个range或者一个值的列表,或者内部hash函数,或者线性hash函数。这个方法根据用户指定的分区类型决定,参数为用户提供表达式的值。这个表达式可以是一个列的值,可以是一个或者多个列的值,也可以是列值的集合,根据分区类型决定。
比如RANGE,LIST,[LINEAR]HASH分区,把分区列传递到分区函数,然后返回一个整型表示该行应该存放的分区号。函数必须是非常量或者非随机。也不能包含查询但是可以使用SQL表达式只要表达式返回要不是NULL要不是整型数据。
对于[LINEAR] KEY,RANGE COLUMNS,LIST COLUMNS分区,分区表达式由一个或者多个列组成。
对于[LINEAR] KEY表达式,分区函数由MySQL提供。
这个就是水平分区,对于垂直分区目前不支持。大多数存储引擎是支持分区的,MySQL分区引擎是独立的一层,可以和其他引擎进行交互。在MySQL 5.7一个表的所有分区必须使用相同的引擎。以下引擎不支持分区:MERGE,CSV,FEDERATED存储引擎。
要指定分区存储引擎,和非分区表一样,指定engine参数:
CREATE TABLE ti (id INT, amount DECIMAL(7,2), tr_date DATE)
ENGINE=INNODB
PARTITION BY HASH( MONTH(tr_date) )
PARTITIONS 6;
每个分区都可以指定存储引擎,但是在MySQL 5.7中没有效果。
每个分区的数据和索引可以适应data directory 和index directory选项分配独立的目录。DATA DIRECTOY和INDEX DIRECTORY对于windows的myisam存储引擎不支持。Innodb所有平台都支持。
分区表达式中的涉及到的列必须是唯一索引的一部分,包括主键。也就是说以下表不能创建分区:
CREATE TABLE tnp (
id INT NOT NULL AUTO_INCREMENT,
ref BIGINT NOT NULL,
name VARCHAR(255),
PRIMARY KEY pk (id),
UNIQUE KEY uk (name)
);
因为pk,uk没有相同的列,没有列可以用来作为分区列。要么pk上加上name,id加到uk,也可以直接删掉uk。
分区表的一些好处:
1.分区表可以把一个表的数据分散到不同的文件系统或者磁盘中。
2.分区表的数据比较容易删除,可以直接删除一个分区。
3.如果where子句可以满足分区列,那么查询性能会得到提升。
其他的好处:
1.聚合函数,如果在分区表上可以并发。
2.数据分散在多个磁盘上,加大查询的吞吐量。
20.2 分区类型 20.2.1 RANGE分区安装RANGE分区表的,行会根据RANGE的划分存放到分区中。RANGE是连续的但是没有重叠,使用VALEUS LESS THAN定义。对于store_id进行分区:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
在这个分区框架,所有的行store_id从1到5都保存在p0分区中,6到10保存在p1中类推。在这里如果插入21就会报错因为没有地方存放这个记录。可以做一下修改存放大记录:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
MAXVALUE表示最大值,比int型最大值还要大。所以大于16的都会被放在p3分区中。分区列也可以使用表达式:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY RANGE ( YEAR(separated) ) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
那么在1991年之前离职的员工都会保存在p0依次类推。如果分区列时个时间戳字段,可以如下分区:
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
RANGE在以下场景下非常有用:
1.想要删除老的数据,刚好在p0上,那么可以直接alter table employee drop partition p0删除分区,达到删除数据的目的
2.想要使用包含时间或者日期的列,或者其他连续的升序列。
3.想要频繁的根据分区列进行查询。可以快速的定位到某个分区。
有个RANGE分区的变种RANGE COLUMNS,可以多个列一起决定一个分区。
20.2.2 LIST分区很多情况下range分区和list分区很像。LIST和RANGE的区别是LIST是一组值,RANGE是一组连续的区间。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
LIST分区删除数据也会很快比如要删除pWest分区数据,用阶段分区比delete快。和RANGE不同没有MAXVALUE。所有的值都要在分区里面,不然就报错。
mysql> CREATE TABLE h4 (
-> c1 INT,
-> c2 INT
-> )
-> PARTITION BY LIST(c1) (
-> PARTITION p0 VALUES IN (1, 4, 7),
-> PARTITION p1 VALUES IN (2, 5, 8)
-> );
Query OK, 0 rows affected (0.11 sec)
mysql> INSERT INTO h4 VALUES (3, 5);
ERROR 1525 (HY000): Table has no partition for value 3
报错的时候,如果表示innodb表就会全部回滚。如果是非事务表,错误之前都插入了,之后的都没插入。
也可以通过IGNORE关键字,对错误行进行忽略,这样错误行就会自动被忽略,正常行就可以被全部插入。
mysql> TRUNCATE h4;
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM h4;
Empty set (0.00 sec)
mysql> INSERT IGNORE INTO h4 VALUES (2, 5), (6, 10), (7, 5), (3, 1), (1, 9);
Query OK, 3 rows affected (0.00 sec)
Records: 5 Duplicates: 2 Warnings: 0
mysql> SELECT * FROM h4;
+------+------+
| c1 | c2 |
+------+------+
| 7 | 5 |
| 1 | 9 |
| 2 | 5 |
+------+------+
3 rows in set (0.00 sec)
20.2.3 COLUMNS分区COLUMNS分区是RANGE和LIST的变种。COLUMNS分区可以可以使用多个列作为分解键。2个列都可以用来分配分区。另外RANGE COLUMNS和LIST COLUMNS分区支持费insert定义range或者list项。允许的字段类型如下:
1.所有int类型
2.date和datetime类型
3.字符串类型,char,varchar,binary和varbinary。TEXT和BLOB列不支持分区。
20.2.3.1 RANGE COLUMNS分区RANGE列分区和RANGE分区很像。就是启用了多列range。另外你可以使用其他数据类型,不一定只用int类型。
RANGE COLUMNS和RANGE明显的区别有以下几点:
1.RANGE COLUMNS不能用表达式,只能是列名
2.RANGE COLUMNS可以使用一个或者多个列。
3.RANGE COLUMNS分区列可以不是int类型。
mysql> CREATE TABLE rcx (
-> a INT,
-> b INT,
-> c CHAR(3),
-> d INT
-> )
-> PARTITION BY RANGE COLUMNS(a,d,c) (
-> PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
-> PARTITION p1 VALUES LESS THAN (10,20,'mmmm'),
-> PARTITION p2 VALUES LESS THAN (15,30,'sss'),
-> PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
-> );
Query OK, 0 rows affected (0.15 sec)
如创建了一个rcx表,有4个列,a,b,c进行分区。那么如果有一样要插入,根据a,b,c依次对比,来决定放入哪个分区。
20.2.3.2 LIST COLUMNS分区MySQL 5.7支持LIST COLUMNS分区。是LIST分区的变种可以使用非int类型作为分区列,而且可以使用多个列。
20.2.4 Hash分区使用HASH分区可以保证数据均匀的分布在各分区上面。使用RANGE,LIST分区需要显示给定值进行分区。使用hash分区,MySQL会帮你处理。
使用hash分区,使用create table子句PARTITION BY HASH(expr),表达式返回int类型。然后需要指定分区个数,如PARTITIONS 4。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
如果不包含PARTITIONS 那么默认分区个数是1个。
20.2.4.1 LINEAR HASH分区MySQL也支持线性hash分区,和传统分区不一样线性hash利用线性2的指数算法,来代替老的hash函数。
算法大致如下:
num表示分区个数
1.V=POWER(2,CEILING(LOG(2,NUM))),V为num的2的最小幂次的值。
2.N=expr&(V-1)计算分区号
3.如果N>=num,N=N&(ceil(V/2)-1),否则就用N编号的分区。
如表如下:
CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE)
PARTITION BY LINEAR HASH( YEAR(col3) )
PARTITIONS 6;
插入了col3为‘20030414’的列:
V = POWER(2, CEILING( LOG(2,6) )) = 8
N = YEAR('2003-04-14') & (8 - 1)
= 2003 & 7
= 3
(3 >= 6 is FALSE: record stored in partition #3)
如果N>=num那么就需要额外计算,比如:
V = 8
N = YEAR('1998-10-19') & (8-1)
= 1998 & 7
= 6
(6 >= 6 is TRUE: additional step required)
N = 6 & CEILING(8 / 2)
= 6 & 3
= 2
(2 >= 6 is FALSE: record stored in partition #2)
使用线性hash的好处是增加,删除,合并分立分区会比较快,特别是对于T级别的表来说。坏处是不能像传统hash分区一样的数据均匀。
20.2.5 Key分区Key分区和hash分区有点类似,但是和HASH分区有很多不同:
1.KEY不单单是hash
2.如果表有主键,key被用于分区的必须是表主键的一部分。不需要指定分区列。如果没有primary key但是有唯一建那么使用唯一建作为分区列。如果唯一建没有定义为 not null那么就会报错。
CREATE TABLE k1 (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20)
)
PARTITION BY KEY()
PARTITIONS 2;
子分区创建如图:
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
ts表有3个RANGE分区,然后每个range分区有2个hash子分区。表一共有6个分区。
MySQL 5.7可以对RANGE LIST分区的表进行子分区,子分区要不是hash要不是key。
也可以使用通过SUBPARTITION子句显示的指定选项,比如:
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000) (
SUBPARTITION s2,
SUBPARTITION s3
),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s4,
SUBPARTITION s5
)
);
一些注意点:
1.每个分区的子分区个数要一样。
2.如果使用subpartition显示的定义分区,就必须定义所有的分区,否则就会失败。
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990) (
SUBPARTITION s0,
SUBPARTITION s1
),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE (
SUBPARTITION s2,
SUBPARTITION s3
)
);
3.每个子分区必须包含子分区的分区名。
4.分配的子分区名必须在表内是唯一的。
20.2.7 MySQL分区如何处理NULL在MySQL分区中,null会被认为小于任何非null的值和order by 一样。
RANGE分区处理NULL
RANGE分区中,NULL值会被放入最小的分区中。
LIST分区处理NULL
list分区中,如果分区list没有null值,插入就会报错。需要在分区list中指定null存放的位置。
Hash和Key分区NULL处理
hash和Key分区对NULL的处理方法和上面的不同,HASH和KEY会把null当成0来处理。
20.3 分区管理 20.3.1 RANGE和LIST分区管理首先删除分区,删除一个分区可以直接用alter table … drop partition来实现。但是删除分区权限需要有表的drop权限。
如果要修改分区,但是不想丢失数据可以使用alter table …reorganize partition语句。
删除分区之后表结构变换,可以使用show create table来查看表结构变化。
如果使用range分区,要增加一个高端的分区可以使用alter table …add partition语句,比如:
CREATE TABLE members (
id INT,
fname VARCHAR(25),
lname VARCHAR(25),
dob DATE
)
PARTITION BY RANGE( YEAR(dob) ) (
PARTITION p0 VALUES LESS THAN (1970),
PARTITION p1 VALUES LESS THAN (1980),
PARTITION p2 VALUES LESS THAN (1990)
);
那么要增加一个2000的分区可以使用如下语句:
ALTER TABLE members ADD PARTITION (PARTITION p3 VALUES LESS THAN (2000)
但是如果要加一个小端的分区比如1960,那么就不能在使用这个语句,要重新整理分区才行,语句如下:
ALTER TABLE members
REORGANIZE PARTITION p0 INTO (
PARTITION n0 VALUES LESS THAN (1960),
PARTITION n1 VALUES LESS THAN (1970)
);
P0分区会被分为n0,n12个分区。
对于list分区可以直接通过alter table…add partition添加分区。但是如果list值里面已经包含在老的分区中就会报错。如果需要拆分已有的分区也需要使用alter table … reorganize partition语句。
语法如下:
ALTER TABLE tbl_name
REORGANIZE PARTITION partition_list
INTO (partition_definitions);
使用alter table… reorganize partition的时候有以下几个注意点:
1.Partition子句用来定义性分区的和create table的规则是一样的。
2.partition_Definitions中的分区定义要能够覆盖partition_list的分区。
3.对于range分区,partition_list必须是连续的不能跳过中间的一个分区。
4.修改表的分区类型不能通过alter table…reorganize partition,也不能修改分区的表达式或者列。只能通过语句修改:
ALTER TABLE members
PARTITION BY HASH( YEAR(dob) )
PARTITIONS 8;
被hash或者key分区的分区表不能删除分区。但是可以通过alter table…coalesce partition语句合并分区。如:
CREATE TABLE clients (
id INT,
fname VARCHAR(30),
lname VARCHAR(30),
signed DATE
)
PARTITION BY HASH( MONTH(signed) )
PARTITIONS 12;
表有12个分区,那么可以通过以下语句把分区收缩到4个。
mysql> ALTER TABLE clients COALESCE PARTITION 4;
Query OK, 0 rows affected (0.02 sec)
Alter table…coalesce partition可以使用在hash,key,linear hash或者linear key。
如果Alter table…coalesce partition指定了大于现在分区的个数,就会报错。
如果要增加分区可以使用alter table…add partition实现:
ALTER TABLE clients ADD PARTITION PARTITIONS 6;
20.3.3移动表的分区和子分区在MySQL 5.7,可以使用alter table pt exchange partition p with table nt 来移动分区。pt表示一个分区表,p是分区或者子分区。移动到非分区表nt。nt的限制条件:
1.nt不是分区表
2.nt不是临时表
3.pt和nt 2个表的表结构一直。
4.nt没有外键约束,也没有其他表引用了nt
5.nt中没有行。如果加了without validation那么就不会验证这个条件。
需要alter,insert,create,drop的权限。
Alter table…exchange partiton注意点:
1.这个语句执行的时候不会调用任何触发器。
2.auto_increment会被重置
3.ignore关键字在这个语句的时候不会起作用。
如:
CREATE TABLE e (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30)
)
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (50),
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (150),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
INSERT INTO e VALUES
(1669, 'Jim', 'Smith'), (337, 'Mary', 'Jones'),
(16, 'Frank', 'White'), (2005, 'Linda', 'Black');
mysql> CREATE TABLE e2 LIKE e;
Query OK, 0 rows affected (1.34 sec)
mysql> ALTER TABLE e2 REMOVE PARTITIONING;
Query OK, 0 rows affected (0.90 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SELECT PARTITION_NAME, TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 1 |
| p1 | 0 |
| p2 | 0 |
| p3 | 3 |
+----------------+------------+
4 rows in set (0.00 sec)
mysql> ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2;
Query OK, 0 rows affected (0.28 sec)
mysql> SELECT PARTITION_NAME, TABLE_ROWS
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME = 'e';
+----------------+------------+
| PARTITION_NAME | TABLE_ROWS |
+----------------+------------+
| p0 | 0 |
| p1 | 0 |
| p2 | 0 |
| p3 | 3 |
+----------------+------------+
4 rows in set (0.00 sec)
mysql> SELECT * FROM e2;
+----+-------+-------+
| id | fname | lname |
+----+-------+-------+
| 16 | Frank | White |
+----+-------+-------+
1 row in set (0.00 sec)
20.3.4 管理分区1.重建分区。就好像删除表内所有数据,然后重新插入,减少碎片
ALTER TABLE t1 REBUILD PARTITION p0, p1;
2.优化分区。如果删除了大量数据或者修改了大量数据,使用语句回收不适用空间,减少碎片,innodb不支持对单个分区进行优化,使用rebuild和analyze代替。
ALTER TABLE t1 OPTIMIZE PARTITION p0, p1;
3.分析分区,读取key在分区的分布
ALTER TABLE t1 ANALYZE PARTITION p3;
4.修复分区数据。当分区有重复键的时候修复会报错。在MySQL 5.7.2之后可以使用alter ignore table,因为重复键问题导致不能应用的都会被删除。
ALTER TABLE t1 REPAIR PARTITION p0,p1;
5.检查分区。和检查表一样检查分区是否有问题
ALTER TABLE trb3 CHECK PARTITION p1;
这个命令会告诉你分区在表上是否正常,如果有错误运行alter table…repair进行修复。Check partition在用有重复键的时候会检查失败。同上用alter ignore table进行处理。
20.3.5 获取分区的信息获取分区的方法有以下几个:
1.使用show create table
2.使用show table status
3.查询information_schema.partitions表
4.使用explain parititons select查看那些分区被select。
CREATE TABLE trb1 (id INT, name VARCHAR(50), purchased DATE)
PARTITION BY RANGE(id)
(
PARTITION p0 VALUES LESS THAN (3),
PARTITION p1 VALUES LESS THAN (7),
PARTITION p2 VALUES LESS THAN (9),
PARTITION p3 VALUES LESS THAN (11)
);
mysql> EXPLAIN PARTITIONS SELECT * FROM trb1G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: trb1
partitions: p0,p1,p2,p3
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 10
Extra: Using filesort
这种情况下所有的4个分区都被使用了,如下语句就只是用了2个分区:
mysql> EXPLAIN PARTITIONS SELECT * FROM trb1 WHERE id < 5G
*************************** 1. row ***************************
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/mysql/12169.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 这些文件如果在configure命
这些文件如果在configure命
时间:2021-01-22
-
 说明在数据库崩溃时内存
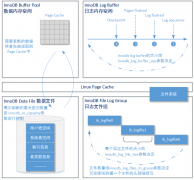
说明在数据库崩溃时内存
时间:2021-01-22
-
 破解极验(geetest)验证码
破解极验(geetest)验证码
时间:2021-01-22
-
 今天这种代码阅读方法仍
今天这种代码阅读方法仍
时间:2021-01-22
-
 count(*) as cnt from sakila.fi
count(*) as cnt from sakila.fi
时间:2021-01-22
-
 可能你注意到系统提示的
可能你注意到系统提示的
时间:2021-01-22
-
 搭建环境与运行
搭建环境与运行
时间:2021-01-22
-
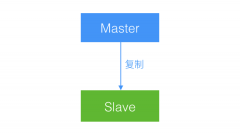 MySQL主从复制的常见拓扑
MySQL主从复制的常见拓扑
时间:2021-01-22
热门文章
-
 MySQL的CRUD操作+使用视图
MySQL的CRUD操作+使用视图
时间:2021-01-10
-
 NodeJs(2)和MySQL(windows下)
NodeJs(2)和MySQL(windows下)
时间:2021-01-05
-
 详解MySQL开启远程连接权限
详解MySQL开启远程连接权限
时间:2021-01-05
-
 MySQL查询优化:LIMIT 1避免全表扫描提高查询
MySQL查询优化:LIMIT 1避免全表扫描提高查询
时间:2020-12-07
-
 MySQL数据检索+查询+全文本搜索
MySQL数据检索+查询+全文本搜索
时间:2021-01-10
-
 mysql安装图解 mysql图文安装教程(详细说明
mysql安装图解 mysql图文安装教程(详细说明
时间:2020-12-23
-
 MySQL8新特性:降序索引详解
MySQL8新特性:降序索引详解
时间:2020-12-23
-
 对于innodb存储引擎的表只能指定数据路径
对于innodb存储引擎的表只能指定数据路径
时间:2021-01-20
-
 MySQL死锁套路之唯一索引下批量插入顺序
MySQL死锁套路之唯一索引下批量插入顺序
时间:2020-12-28
-
 可以通过动作标识来引用 DROP TABLE IF EXI
可以通过动作标识来引用 DROP TABLE IF EXI
时间:2021-01-20