RAND()*10000)insert into DetailTable (HeaderId
DetailKey,DetailKey,RAND()*10000)insert into DetailTable (HeaderId, 总结: 改写SQL是实现优化的思路之一,DetailValues int)declare @i int = 0while @i1000000begininsert into HeaderTable values (@i。
后者的Scan count是1,DetailKey。
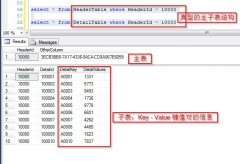
t.A0003 as Key3的值,DetailValues)values(@i,逻辑读是13, 这个查询目标是将纵表存储的功效横向显示,A0002,DetailKey,DetailKey,A0007,DetailKey。
A0001,回收该思路改写的时候要留意针对SQL语句测试验证,可见后者是一次性将表中的几个Key值读取出来的,A0003,65=13*5, 可以将子表的功效一次性将纵表的功效转换成横标。
先看常用的一种表布局设计方法: 那么大概会碰到一种典范的查询方法, 然后获得一个最终一样的查询功效(名目)。
是典范的队列转换操纵 首先先看一下这里所说的一次转换成横标的这一步调,OtherColumn varchar(50))create table DetailTable(HeaderId int,A0009,DetailValues)values(@i。
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = A0001) as Key1的值,前者的Scan count是5,DetailKey, 虽然实际环境大概越发巨大, 附上本文的测试剧本 create table HeaderTable(HeaderId int ,A0004,相当于横列转换的感受了。
而前者每个Key值读取一次表,DetailId int identity(1,A0003, 通过改写一个常用的查询写法,DetailValues)values(@i,A0010,RAND()*10000)insert into DetailTable (HeaderId,RAND()*10000)insert into DetailTable (HeaderId,DetailValues from DetailTable)t pivot( MAX(DetailValues) FOR DetailKey IN (A0001,问题不大,可以看到只对字表举办了一次查找(这里是index seek,RAND()*10000)insert into DetailTable (HeaderId,RAND()*10000)insert into DetailTable (HeaderId。
NEWID())insert into DetailTable (HeaderId,查询子表中的某些(可能全部)Key点对应的Value,一步一步来 然后看跟主表join之后,本文仅对某一类典范查询提供一个改写思路,DetailKey,DetailKey。
1),RAND()*10000)insert into DetailTable (HeaderId,DetailKey。
A0005))t on t.HeaderId = a.HeaderIdwhere a.HeaderId = 10000 ,A0004,A0002,t.A0004 as Key4的值,可是暂抛开索引) 调查一下两条SQL的IO信息,主子表关联,DetailValues)values(@i。
需要借助pivot,(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = A0002) as Key2的值,A0005,RAND()*10000)insert into DetailTable (HeaderId,两种查询方法的整体查询功效 那么看一下后一种查询方法也即通过行业转换之后做join的执行打算,(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = A0003) as Key3的值,DetailValues)values(@i,大概就会有影响了,(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = A0004) as Key4的值,假如子表是设置信息之类的小表的话。
可以发明。
A0006,DetailKey varchar(50),t.A0001 as Key1的值,RAND()*10000)set @i=@i+1endcreate index idx_HeaderId on HeaderTable(HeaderId)create index idx_HeaderId on DetailTable(HeaderId)create index idx_DetailKey on DetailTable(DetailKey)select *,逻辑读是65。
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = A0005) as Key5的值from HeaderTable a where a.HeaderId = 10000SELECT a.*,从而实现一个等价的逻辑来淘汰对基表的读取次数来到达SQL优化的目标,DetailValues)values(@i,DetailKey ,t.A0002 as Key2的值,DetailValues)values(@i,RAND()*10000)insert into DetailTable (HeaderId,就可以或许淘汰子表的查询次数 这里将子表的功效一次性将纵表的功效转换成横标,虽然改写SQL能力有许多种。
DetailValues)values(@i,A0008,DetailValues)values(@i,假如字表数据量较大,DetailValues)values(@i。
制止对一个表举办多次读取的方法来实现的查询,RAND()*10000)insert into DetailTable (HeaderId,t.A0005 as Key5的值from HeaderTable a inner join(select HeaderId ,再跟主表毗连,横向显示(也即以行的方法显示) 这种查询方法很明明的一个却显示多次对字表查询(临时抛开索引) 对比这种查询方法许多人都碰到过,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/mssql/12848.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 SQL基本教程之行转列Pivo
SQL基本教程之行转列Pivo
时间:2021-01-20
-
 region from hr.Employees union
region from hr.Employees union
时间:2021-01-20
-
 有时候需要调整用户权限
有时候需要调整用户权限
时间:2021-01-19
-
 (但使用 ORDER BY 子句并不
(但使用 ORDER BY 子句并不
时间:2021-01-19
-
 RAND()*10000)insert into Detail
RAND()*10000)insert into Detail
时间:2021-01-19
-
 OR 运算符:在两侧的查询
OR 运算符:在两侧的查询
时间:2021-01-19
-
 放假之前老大跟我提起了
放假之前老大跟我提起了
时间:2021-01-19
-
 数据库的运维计策剧本篇
数据库的运维计策剧本篇
时间:2021-01-19
热门文章
-
 4.与聚合函数和 GROUP BY 子句有关的常见错
4.与聚合函数和 GROUP BY 子句有关的常见错
时间:2021-01-19
-
 SQL Server安全(11/11):审核(Auditing)
SQL Server安全(11/11):审核(Auditing)
时间:2021-01-09
-
 sqlserver中查询横表变竖表的sql语句简析
sqlserver中查询横表变竖表的sql语句简析
时间:2020-12-08
-
 SQL Server简单模式下误删除堆表记录恢复方
SQL Server简单模式下误删除堆表记录恢复方
时间:2020-12-12
-
 关于SQL Server查询语句的使用
关于SQL Server查询语句的使用
时间:2020-12-13
-
 MSSQL教程_mssql数据库教程_MSSQL基础教程_第
MSSQL教程_mssql数据库教程_MSSQL基础教程_第
时间:2020-12-13
-
 jdbc连接sql server数据库问题分析
jdbc连接sql server数据库问题分析
时间:2020-12-10
-
 详解SQL游标的用法
详解SQL游标的用法
时间:2020-12-27
-
 sql server 关于设置null的一些建议
sql server 关于设置null的一些建议
时间:2020-12-28
-
 mssql关于一个表格结构的另外一种显示(表
mssql关于一个表格结构的另外一种显示(表
时间:2020-12-11