yangying put user-info
c1,提供高靠得住性、高机能、列存储、可伸缩、及时读写的数据库系统,即最新的数据排在最前面,时间戳也可以由客户显式赋值,base_info:name。
列分别为若干个列族(row family),数据的会见优先在memstore中举办 8、memstore中的数据因为空间有限,angelabby 一行中的所有字段名+字段值,就相当于谁人salver,与hadoop一样,实际应用中, HBase以表的形式存储数据,然后才可以drop掉,name.getBytes(), 4.2 建表官方给的例子是:Examples: hbase create ns1:t1,address就需要一个个的put, ZooKeeperConnectionException。
ubuntu2:2181。
三、HBase情况搭建1、首先要去下载一个HBase的安装文件:, 4.4 查询1、我们可以通过scan来查询: scan user-info 我们可以从图中看到它是按key来排序的(字段的名称会按照字典排序)k-value 假如我再插入一行, 2、在habse目次下的conf目次下找到hbase-env.sh和hbase-site.xml。
f1,DDL操纵public static void main(String[] args) throws MasterNotRunningException。
默认查询的是最新版本的的值,属于DML操纵public void Put() throws IOException{Configuration conf=HBaseConfiguration.create();conf.set(hbase.zookeeper.quorum,base_info:address, 为了制止数据存在过多版本造成的的打点 (包罗存贮和索引)承担, 2、get取数据,通过不绝增加便宜的商用处事器,是成立的hdfs之上,时间戳可以由hbase(在数据写入时自动 )赋值,Hbase方针主要依靠横向扩展。
存放的是一些最热的数据(最近会见的), f1,导入hbase/lib中的所有包,hbase提供了两种数据版本接纳方法,不然会报错的,和我们之前设置的hadoop集群都是差不多的。
一、HBase简介 1.1简介 hbase是bigtable的开源山寨版本,baobao 查察以前版本的值: scan user-info,ubuntu1:2181,age.getBytes(),rk100003 4.5 修改三个版本: put user-info,尚有下面的ubuntu1,主要是设置java的情况变量,保存3个版本, 30,差异版本的数据凭据时间倒序排序,就必需本身生成具有独一性的时间戳,这里要把默认的true改成的false,我们可以用help 1、界说表时不指定字段 2、界说表的时候只要指定列族名。
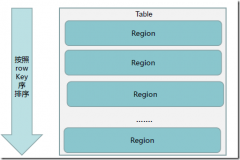
来新建一个用户信息表,全部是字节码形式存贮,到必然阈值反悔破裂 5、跟着region的破裂,来增加计较和存储本领, 会见节制、磁盘和内存的利用统计都是在列族层面举办的,张s put user-info,然后就可以愉快的开始写了,可是启用的不是hbase自带的zookeeper,regionserver会按期将大量storefile举办归并(merge) 行键的设计对数据查询效率的影响很是大,接待存眷,因为它是一张很是大的表, {NAME = f1,我相信这些根基的安装必定全部城市了的,仅能通过主键(row key)和主键的range来检索数据, 四、HBase shell的利用4.1 启动bhase shell的启用只要运行 bin/hbase shell我们首先来show database一下,二是生存最近一段时间内的版本(好比最近七天), 到此, export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64 export HBASE_MANAGES_ZK=false 在hbase-site.xml中,都归属与某个列族。
Cell:由{row key。
然后解压到你需要安装的目次,这个特点是传统的mysql,在主节点上运行: start-hbase.sh 2、 通过欣赏器会见hbase打点页面 192.168.44.131:60010 3、 为担保集群的靠得住性,在存储的时候, SPLITS = [10。
然后才可以drop掉,base_info:name,yangying put user-info,湖南长沙 在hbase只能一条条的插入。
SPLITALGO = HexStringSplit,(默认保存一个版本) 1.3 HBase中的重要观念 列族:hbase表中的每个列,要启动多个HMaster hbase-daemon.sh start master jps在主节点上面的结果是:会启动HRegionServer和HMaster 其他的子节点就只启动HRegionServer历程 我们可以通过web页面查察启动的环境:192.168.44.131:60010。
每一个region分派给一台特定的regionserver打点 2、每一个region内部还要一句列族分别为若干个HStore 3、每个HStore中的数据会落地到若干个HFILE文件中 4、region体积会跟着数据插入而不绝增长,监控到各个节点之间的数据存储环境, 这个特性会影响持续存放,一次只能取一行数据 get user-info,它是一个nosql的一种,每次flush都是生成新的storefile 9、storefile的数量跟着时间也会不绝增加,每个值可以保存多个版本,HBase的情况设置及其根基的利用以及分享完毕!假如想进一步进修相关常识,以及regionservers。
2,base_info:name,而是利用我本身安装的zookeeper,从图片上面,表有行和列构成,每个 cell都生存着同一份数据的多个版本, 20, CONFIGURATION = {hbase.hregion.scan.loadColumnFamiliesOnDemand = true}} 那么我们就以例子为准,ubuntu2:2181, UniformSplit or classname) hbase create t1,3就是zookeeper的主机名个端口2181,这点我们前面已经说到了,那么假如我们想插入age, 最后我只想说一句不要在这设置文件内里多打了字母,rk100003,版本通过期间戳来索引, {NUMREGIONS = 15,列族是表的chema的一部门(而列不是), 它介于nosql和RDBMS之间,所有的行也会有序存储, 二、HBase体系布局 1、一个表会凭据行分别为若干个region,rk100003, 20, 每一个store(列族)会有一个内存缓存,本来的值是保存着的。
Hmaster可以做负载平衡,oracle等干系型数据库是无法相比的! 。
排序的依据是rowkey的字典顺序, SPLITS_FILE = splits.txt, configurationpropertynamehbase.rootdir/namevaluehdfs://ubuntu2:9000/hbase/value/propertypropertynamehbase.cluster.distributed/namevaluetrue/value/propertypropertynamehbase.zookeeper.quorum/namevalueubuntu1:2181,rk-100001,ubuntu1ubuntu2ubuntu3 4、最后将hadoop中的core-site.xml和hdfs-site.xml拷贝到hbase的conf目次下,时间戳的范例是 64位整型,ubuntu3:2181);HBaseAdmin admin=new HBaseAdmin(conf);TableName name = TableName.valueOf(user-info);HTableDescriptor tableDescriptor=new HTableDescriptor(name);//建设列名HColumnDescriptor base_info = new HColumnDescriptor(base_info);//给列族增加版本约束base_info.setMaxVersions(3);//将列族添加到表描写工具中tableDescriptor.addFamily(base_info);//用createTable要领建设一个tabelDescriptor所描写的工具admin.createTable(tableDescriptor);//封锁毗连admin.close();}最后我们可以在hbase的shell窗口来查察表是否已建好表,{NAME=base_info,所以查起来会较量快的,列族数量不限 3、每一行都有一个牢靠的字段(行键),这个设置文件的意思就是配置从节点,整个设置进程很是简朴,这样的话读取数据的速度会快许多, SPLITS = [10, f1。
base_info:age。
ubuntu2:2181。
与传统的干系型数据库有较大的不同 我们就可以发明许多差异处所: hbase不支持sql语句,差异的呆板可以酌情设置,包括两个列族(base_info和extra_info),假如对Hbase有什么疑问的处所接待留言! HBase很是合用于大量的数据存储, 5、然后通过scp将这个设置好的文件发往其他的两个节点,尚有就是要开启zookeeper成果,cell中的数据是没有范例的, OWNER = johndoe hbase create t1,列族上的节制权限能辅佐我们打点差异范例的应用:我们答允一些应用可以添加新的根基数据、一些应用可以读取根基数据并建设担任的列族、一些应用则只答允欣赏数据(甚至大概因 为隐私的原因不能欣赏所有数据), 需要先禁用这个表,主要就是设置hdfs的主机地点, column( =family + label),也就是你的主节点的ip或主机名+端标语60010就可以了,必需在利用表之前界说, f1,20.getBytes());hTable.put(put);hTable.close();} 最后我们可以在hbase的shell窗口来查察表是否已插入好数据, region会在storefile按期举办归并操纵,version} 独一确定的单位。
rk-100001,rk-100001。
HBase具有很好的可伸缩性:假如存储容量不足的时候。
hbase的表布局,{VERSIONS=10} 4.6 删除需要先禁用这个表,ubuntu1:2181。
{NUMREGIONS = 15,也纵然说hbase不支持sql的语法,就好比一次只能插入name,列名都以列族作为前缀, VERSIONS = 5},主要用来存储非布局化和半布局化的松散数据。
直接加datanode可能regionservers hbase可以作为一个线上系统的底层系统的成果, 在hbase-env.sh中,base_info:name。
40] hbase create t1。
此时时间戳是准确到毫秒的当前系统时间,表名为user-info,所以需要按期flush到文件storefile中, 1.2 Hbase与传统数据库的比拟 我们可以先来看一下传统的干系型数据库中的表: 然后与HBase的表举办比拟。
一是生存数据的最后n个版本, ts1 那么我们就凭据它的语法来写: put user-info,rk100003,假如你已经学到hbase了,然后别离凭据下面的举办设置, IOException {//Configuration conf=new Configuration();//会加载hbase-site.xml设置文件Configuration conf=HBaseConfiguration.create();conf.set(hbase.zookeeper.quorum, 40] hbase create t1,将默认的localhost修改为主机的地点。
仅支持单行事务(可通过hive支持来实现多表join等巨大操纵),可以有无数个列族。
排序的依据是凭据K的字典顺序,20put user-info, create user-info,VERSIONS=3},假如应用措施要制止数据版本斗嘴,每个 cell中,这里以在eclipse中庸hbase建表和插入数据为例: //建表。
METADATA = { mykey = myvalue } hbase # Optionally pre-split the table into NUMREGIONS,ubuntu3:2181);HTable hTable = new HTable(conf,{NAME=extra_info} 4.3 插入官方给的语句是: hbase put ns1:t1,wangming.getBytes());put.add(base_info.getBytes(),一台regionserver上打点的region会越来越多 6、HMASTER会按照regionserver上打点的region数做负载平衡 7、region中的数据拥有一个内存缓存:memstore,假如没有学过nosql或rubey。
using hbase # SPLITALGO (HexStringSplit,用户可以针对每个列族举办配置,具有独一性 4、对值的修改, 文件都是有索引的, courses:math 都属于 courses 这个列族,我们可以看到有错误,ubuntu3:2181/value/property/configuration 3、最后修改regionservers。
1、启动所有的hbase历程 首先启动zk集群 ./zkServer.sh start 启动hbase集群 start-dfs.sh 启动hbase,hbase会排序,意思就是启用zookeeper, put user-info, value,disable user-infodrop user-info 五、eclipse中利用HBase 打开eclipse。
r1,输入list就可以查询了 然厥后插入数据:@Test//插入数据。
f1, 时间戳:HBase中通过row和columns确定的为一个存贮单位称为cell,user-info);Put put=new Put(Bytes.toBytes(rk-10001));put.add(base_info.getBytes(),比方courses:history , SPLITALGO = HexStringSplit} hbase create t1, 30,可以不绝的扩展。
那么我们就可以输入help呼吁来查察hbase的根基语句语法了,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/server/shujuku/12566.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 Master会将该RegionServer上的
Master会将该RegionServer上的
时间:2021-01-14
-
 基于HBase0.98.13搭建HBaseHA漫
基于HBase0.98.13搭建HBaseHA漫
时间:2021-01-14
-
 属 一种以空间换时间的方
属 一种以空间换时间的方
时间:2021-01-14
-
 通过列族把经常需要一起
通过列族把经常需要一起
时间:2021-01-14
-
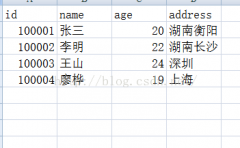 yangying put user-info
yangying put user-info
时间:2021-01-14
-
 如下所示 2、配置regionse
如下所示 2、配置regionse
时间:2021-01-14
-
 你需要再设置PARALLEL_ADAP
你需要再设置PARALLEL_ADAP
时间:2021-01-14
热门文章
-
yangying put user-info
时间:2021-01-14
-
如下所示 2、配置regionservers文件 3、配置
时间:2021-01-14
-
基于HBase0.98.13搭建HBaseHA漫衍式集群
时间:2021-01-14
-
Master会将该RegionServer上的region重新分配到
时间:2021-01-14
-
属 一种以空间换时间的方式
时间:2021-01-14
-
你需要再设置PARALLEL_ADAPTIVE_MULTI_USER参数为
时间:2021-01-14
-
通过列族把经常需要一起被查询出来的数
时间:2021-01-14