其块尺寸为65536. DEFAULT COLUMN ENCODING (compresstype=quicklz
而且多次查询的环境, 建设列存表 利用列存的TABLE必需是AO表, 这在处理惩罚数据倾斜问题时大概是很须要的, 4) pg_bitmapindex模式 一个储存bitmap index工具的处所(值列表等), 5) pg_aoseg模式 一个储存append-only表的处所, COLUMN l ENCODING(COMPRESSTYPE=ZLIB)) ( PARTITION p1 START(1) END(10),而行存表是存储在同一个磁盘文件), CREATE TABLE sales (trans_id int, dept ... WHERE state=CA 建设行存表 在CREATE TABLE时利用WITH子句来指明TABLE的存储模式,下表是可用的压缩算法: 表导向 | 可用压缩范例 | 支持压缩算法 --------|------------------|------------------------------- 行 | 表级别 | ZLIB 和 QUICKLZ --------|------------------|--------------------------------- 列 | 列级别 和 表级别 | RLE_TYPE、 ZLIB 和 QUICKLZ 利用库内压缩要求Segment系统具备强劲的CPU来压缩息争压缩数据, c3 char, RLE压缩处理惩罚这种数据为雷同data1 200000 data2 400000这样的结果, 5, ALTER TABLE sales SET SUBPARTITION TEMPLATE (); 11) 建设与利用序列 (1)建设序列 CREATE SEQUENCE myserial START 101; (2)利用序列 获取序列的下一个值并插入表中: INSERT INTO vendors VALUES (nextval(myserial), compresslevel=5); 查抄AO表的压缩与漫衍环境 ------------------------------------------------------------------------------------------------------------------------ select get_ao_distribution(name); | Set of (dbid, 建设模式 CREATE SCHEMA zhangyun_schema; CREATE SCHEMA zhangyun_schema AUTHORIZATION zhangyun; 模式搜索路径 要知道在DB的哪个模式下搜索需要的工具, PARTITION Jun08 START (date 2008-06-01) INCLUSIVE ,从头加载数据到新的表, ALTER TABLE sales SPLIT PARTITION FOR (2008-01-01) AT (2008-01-16) INTO (PARTITION jan081to15。
级别越高, etc text) DISTRIBUTED RANDOMLY; 4) 选择表的存储模式 ######选择堆存储可能只追加存储(Heap Storage or Append-Optimized Storage)###### Heap Storage: 缺省环境下GPDB利用与PostgreSQL沟通的存储模式为堆存储。
gp_toolkit视图对付所有DB User都是可以会见的。
ALTER TABLE sales ALTER PARTITION FOR (RANK(1)) ADD DEFAULT PARTITION other; ALTER TABLE sales ALTER PARTITION FOR (RANK(2)) ADD DEFAULT PARTITION other; ALTER TABLE sales ALTER PARTITION FOR (RANK(3)) ADD DEFAULT PARTITION other; RANK(partitionrank)指的是范畴分区同一层级中的顺序,第2个分区名称必需是已经存在的默认分区,每个块尺寸意味着相应数量byte的存储。
date date,2), 表分区是一种大表逻辑切分和数据客栈任务的东西,分区法则利用等值较量,而对写操纵没有优化, CREATE TABLE products (product_no integer UNIQUE,仅仅在层级最低的子分区中有数据,9 级压缩较慢但压缩率较高 | | QUICKLZ 仅 1 个级别可选(缺省不需指定) | | RLE_TYPE 为 1-4 级可选 | | 1 级压缩较快但压缩率较低,那么就选择行存表,假如将漫衍计策改为随机漫衍时也会从头漫衍数据,要添加新的分区只能从默认分区拆分。
可以查察和检索系统日志文件和其他的系统信息,对付列表分区。
这种表大概会在初始化妆载后常常更新数据,还可以先建设一其中间表、装载数据、然后与分区表举办分区互换,因此多分区表和列存储表城市耗损更多的内存, SUBPARTITION europe VALUES (europe) ); 子表的名称名目如下: 父表名称_分区层级_prt_分区名称 子表的名称不能通过直接执行ALTER表名来实现, CREATE TABLE products (name varchar(40)。
这样比直接装载数据要快许多, compresslevel=1, 指定的支解值对应的数据将进入后头一个分区(就是STAER为INCLUSIVE),可能随意的修改分区界说, 查抄序列当前的计数配置, k date, CREATE TABLE sales (id int, prod_id integer, fselocation as datadir FROM pg_tablespace pgts,可是不要执行并行批量的update或delte操纵, blocksize=65536),可以通过配置search_path参数来完成, region text) DISTRIBUTED BY (id) PARTITION BY RANGE (year) SUBPARTITION BY RANGE (month) SUBPARTITION TEMPLATE ( START (1) END (13) EVERY (1),办理步伐就是将表分成许多小且更容易打点的部门, output = comptype_out, gp_toolkit视图包括一些外部表、视图、函数, month int, year int,必需为每个分区指定相应的值。
在选择COLUMN级别压缩时。
update不频繁, 在修改了子分区模版之后添加的分区, alignment = int4。
acme); 可以利用setval函数重置一个序列计数器的值,要查察结果,该模式仅供GPDB系统内部利用,因此。
COLUMN i ENCODING(COMPRESSTYPE=ZLIB), 该模式仅供GPDB系统内部利用, PARTITION Dec08 START (date 2008-12-01) INCLUSIVE END (date 2009-01-01) EXCLUSIVE ); 上面的分区的范畴都是持续的, tuplecount) rows | 展示 AO 表的漫衍环境,别的还必需从头授权表的权限,2500033) (3,2500033) (0, 不管分区是否持续(中间有值不匹配分区), input = comptype_in,凡是先删除索引、再装载数据、然后在从头建设索引,假如没有建设其他的模式。
需要留意的是,不要在AO表上执行单条的insert, 缺省环境下, 查察分区设计 要查察分区表的设计环境,思量选择行存表,2500037) (0,并且还大概会显著的增加存储文件的尺寸,拥有给定表空间CREATE权限的Role必需通过表空间的名称作为相关呼吁的参数来实现, 模式可以答允用户在一个DB内差异的模式之间利用沟通Name的工具(好比Table, (3) 查询涉及的COLUMN数量 若凡是在SELECT可能WHERE中涉及TABLE的全部或大部COLUMN。
View等), fsedbid as seg_dbid, 可以通过SQL的方法会见它们。
pg_catalog; 2) 查察当前的模式 SELECT current_schema(); SHOW search_path; 系统模式 下面的这些系统级此外模式在所有的DB中都存在: 1) pg_catalog模式 存储着系统日志表(System Catalog Table)、 内置范例(Type)、函数(Function)和运算符(Operator), amt decimal(10, ALTER TABLE sales SPLIT DEFAULT PARTITION START (2009-01-01) INCLUSIVE END (2009-02-01) EXCLUSIVE INTO (PARTITION jan09, 别的。
j int, 可是,好比: CREATE TABLE sales (id int。
而独一索引可以不包括分区键, 列表分区可以利用多个COLUMN(组合起来)作为分区键, CREATE TABLE rank (id int,好比日期或价值)分区和列表(按照值列表分区, CREATE TABLE test (id int, 在内部, 因此,实际上是建设了一张顶层(父级)表和多个低层 (子级)表,4 级压缩较慢但压缩率较高 ----------------------------------------------------------------------------------------------------------- BLOCKSIZE | 表的存储块巨细 | 8192 209715(8K 2M)该值必需是 8192 的倍数 ----------------------------------------------------------------------------------------------------------- 利用存储参数的名目如下: [ ENCODING ( storage_directive [,常用于数据在初始装载后常常变革, 对付Numeric范例来说。
固然在界说TABLE时看起来精简了不少,选择BIGINT范例来存储SMALLINT范例范畴内的数值, 可以将CREATE权限授予相应的用户, 重建表上的全部索引 REINDEX my_table; 重建特定的索引 REINDEX my_index; (3)删除索引 在装载数据时。
其子分区将凭据新的模版发生。
占用磁盘空间少, 建设堆表 行存堆表是缺省的存储模式: CREATE TABLE test (id int, SUBPARTITION europe VALUES (europe), 这些表空间利用系统缺省的文件空间pg_system(系统初始化时利用的数据目次data directory), supplier_id integer) DISTRIBUTED BY (prod_id); CREATE TABLE random_stuff (things text,在多级分区表中, amount decimal(9,会造成空间的大量挥霍,修改表的存储模式是不行能的, ALTER TABLE sales SET SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES (usa),块尺寸必需在8192到2097152之间。
blocksize=65536) DEFAULT COLUMN ENCODING (compresstype=quicklz) 示例: CREATE TABLE T1 ( c1 int ENCODING (compresstype=zlib),要想对现有的表做分区。
还必需从头对TABLE做授权,这里表sales被分区为年、月、区域, 界说数字范畴分区表 数字范畴分区表利用单个数字列作为分区键, CREATE TABLE products (product_no integer PRIMARY KEY,大概需要利用REINDEX呼吁重建索引,这些表凡是都是系统中最大的表,2500004) (2,假如不持续需要指定end值。
但压缩率不如ZLIB,但对付别人来说,这种分区互换的机能高于直接的COPY和INSERT, default partition); (6)修改子分区模版 利用ALTER TABLE SET SUBPARTITION TEMPLATE呼吁来修改现有分区表的子分区模版,2500033) (2。
(2)打点索引 更新和删除操纵不更新位图索引,2499970) (1,好比,2499970) (2,2499974) select get_ao_compression_ratio(25626); get_ao_compression_ratio -------------------------- 4.76 支持运行长度编码 GPDB已支持COLUMN级此外运行长度编码(Run-length Encoding /RLE)压缩算法。
name text, region text) DISTRIBUTED BY (trans_id) PARTITION BY RANGE (date) SUBPARTITION BY LIST (region) SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES (usa)。
我们就可以基于表空间来建设数据库 create database zhangyun_db with OWNER zhangyun template template0 encoding utf8 tablespace zhangyun_tbs ; 4. 利用表空间存储 DB 工具 表、索引、甚至整个DB都可以指定在特定的表空间。
b text) WITH (appendonly=true。
SUBPARTITION TEMPLATE子句确保每个年分区有沟通的子分区布局, 因此,不推荐一行一行的利用INSERT语句来装载数据, compresstype=zlib, name text) DISTRIBUTED BY (id); Append-Optimized Storage: GPDB还提供了一种称之为只追加存储模式的表, compresstype=quicklz,分区自己不会改变Instance间物理上的数据漫衍纪律, 可以通过利用START值、 END值和EVERY子句界说分区增量让GPDB自动发生分区,2)) DISTRIBUTED BY (id) PARTITION BY RANGE (date) ( START (date 2008-01-01) INCLUSIVE END (date 2009-01-01) EXCLUSIVE EVERY (INTERVAL 1 day) ); 不外也可觉得每个分区单独指命名称, UPDATE和DELETE操纵需要对ROW级别做版本节制从而确保DB事务处理惩罚的靠得住性。
堆存储模式在OLTP范例事情负载的DB中很常用, COLUMN c3 ENCODING (RLE_TYPE) ) WITH (appendonly=true,好比区域或出产线)分区, DEFAULT PARTITION outlying_dates ); 下面是一个3级分区表的例子, 并行的批量insert操纵也是可以的, DEFAULT SUBPARTITION other_regions ) ( START (2002) END (2010) EVERY (1)。
SUBPARTITION rest VALUES(3, 要删除子分区模版,通过pg_partitions视图查察,其块尺寸为65536. DEFAULT COLUMN ENCODING (compresstype=quicklz,淘汰磁盘IO。
8,应该只管选择更小的数据范例来适应数据,2500037) (4 rows) template1=# ALTER TABLE foo SET DISTRIBUTED RANDOMLY; #从头配置漫衍计策 template1=# select get_ao_distribution(foo); get_ao_distribution --------------------- (1, 要获取文件空间的信息,其会拖慢整体的扫表时间,该模式仅供GPDB系统内部利用,2499974) (1, 201); 留意,在大都环境下。
date date,利用REORGANIZW=TRUE。
可通过与pg_tablespace关联查察表空间的完整界说: SELECT spcname as tblspc,对付row的列值被放在磁盘的差异位置。
在CREATE TABLE时利用PARTITION BY(以及可选的SUBPARTITION BY)子句来做分区,没有级别选项可以选择。
] )。
rank int,2500003) (1,2499974) (3,一个日期COLUMN和一个描写COLUMN, 名称 | 表明 | 可选值 COMPRESSTYPE | 利用的压缩范例 | ZLIB(更高压缩) | | QUICKLZ(更快压缩) | | RLE_TYPE(运行长度编码) | | none(无压缩、缺省值) ---------------------------------------------------------------------------------------------------------- COMPRESSLEVEL | 压缩级别 | ZLIB 为 1-9 级可选 | | 1 级压缩较快但压缩率较低,而且独一约束的Column荟萃必需完整包括所有的DK Column。
凡是不发起打点员可能任何用户会见,每个块作为一部门数据来维护,而ZLIB压缩模式有1 9个压缩级别可选,可以查察系统日志表pg_filespace和pg_filespace_entry, 在利用INTO子句时,对付那些没有许多反复值的数据RLE是不适合的。
并且只能从最低层级分区的默认分区拆分(只有包括数据的分区可以拆分), #Vitesse DeepGreen does not support quicklz. Please use lz4 or set vitesse.lz4_replace_quicklz. COLUMN k ENCODING(COMPRESSTYPE=ZLIB),列式存储的每列都是沟通名目标数据值,压缩效率越高,别的一种是COLUMN级此外压缩。
date date。
存储参数可用于行导向和列导向的AO表。
default = 123,表数据会自动从头漫衍, 2) COLUMN j ENCODING (compresstype=RLE_TYPE), name text,凡是都但愿用最小的空间储存数据, orientation=column); CREATE TABLE T3 ( c1 int ENCODING (compresstype=zlib), 4, public, PARTITION Apr08 START (date 2008-04-01) INCLUSIVE , count int) DISTRIBUTED BY (id) PARTITION BY RANGE (year) ( START (2001) END (2008) EVERY (1), k int, 思量列存的环境: 列式存储是对读操纵举办优化的,修改新表为旧的表名,堆表更适合一些小表, 尚有一种大概就是把旧的分区互换为压缩AO表以节减空间, #压缩方法(RLE_TYPE), ,并且不频繁update的表适合利用AO表, PARTITION May08 START (date 2008-05-01) INCLUSIVE ,2500004) (0, 利用列级压缩 在CREATE TABLE、 ALTER TABLE和CREATE TYPE呼吁中包括对COLUMN配置压缩范例、压缩级别和块尺寸(Block Size)的选项, DEFAULT PARTITION outlying_dates ); ALTER TABLE sales ADD PARTITION START (date 2009-02-01) INCLUSIVE END (date 2009-03-01) EXCLUSIVE; 假如在建设TABLE时没有subpartition template, c2 char ENCODING (compresstype=quicklz。
7。
compresslevel=1 ); 不发起利用这种不明明的方法,2500003) (4 rows) template1=# ALTER TABLE foo SET DISTRIBUTED BY (a); #从头配置漫衍计策 ALTER TABLE template1=# select get_ao_distribution(foo); get_ao_distribution --------------------- (1, orientation=column) PARTITION BY RANGE(k) SUBPARTITION BY LIST(j) SUBPARTITION TEMPLATE ( SUBPARTITION one_two VALUES(1, orientation=column); CREATE TABLE T5 ( i int,要重漫衍TABLE的数据, c2 char ENCODING (compresstype=quicklz,删除旧分区并添加一个新的分区。
Table必需是HASH漫衍的(而不是DISTRIBUTED RANDOMLY),不要压缩利用AO表。
选择块尺寸 在一个TABLE中。
假如启用了镜像成果,别的currval和lastval函数今朝未被GPDB支持, orientation=column) PARTITION BY RANGE (c3) ( START (1900-01-01::DATE) END (2100-12-31::DATE), 6) gp_toolkit模式 一个打点用的模式, passedbyvalue,好比维表,其所有相关子分区的数据都自动被清空, price numeric) DISTRIBUTED BY (product_no); 主键约束 在GPDB中利用主键约束存在强制条件, ] ) 比方: C1 char ENCODING (compresstype=quicklz, 在GP中。
前者应用到整个TABLE, 2) 配置Table和Column的约束 查抄约束 CREATE TABLE products ( product_no integer, 6, PARTITION jan0816to31); 假如分区表有默认分区。
GPDB支持范畴(按照数值型的范畴支解数据,比方: 测试: template1=# d+ foo Append-Only Table public.foo Column | Type | Modifiers | Storage | Description --------+---------+-----------+----------+------------- a | integer | | plain | b | text | | extended | Compression Type: zlib Compression Level: 5 Block Size: 32768 Checksum: t Has OIDs: no Options: appendonly=true, 存储参数包括3个部门:参数名称、便是号、参数值,可觉得差异的COLUMN选择差异的压缩算法, 对付规划用来做表关联的Column来说。
DEFAULT PARTITION other ); 界说多级分区表 利用subpartition template来确保每个分区具有沟通的子分区布局。
思量选择行存表, blocksize=65536),只能在CREATE TABLE的时候做分区, date date,2499970) (2, 如下面的CREATE TABLE语句所示: 一般用法: column_name data_type ENCODING ( storage_directive [, SUBPARTITION asia VALUES (asia),好比, RLE压缩有4种级别, CREATE TABLE sales (trans_id int, ALTER TABLE sales SET WITH (REORGANIZE=TRUE); 该呼吁会在Instance之间凭据现有的漫衍计策(包罗随机漫衍计策)从头均衡表中数据, PARTITION Jul08 START (date 2008-07-01) INCLUSIVE , RLE是一种将持续反复的数据作为一种计数方法存储的压缩算法, SUBPARTITION asia VALUES (asia), name text) WITH (appendonly=true); 演示delete和update对ao表的操纵: zhangyun_db=# insert into test values(1, 该模式无论是否在search_path中指明, 别的一本机能晋升的处所是。
缺省环境下所有的ROLE(User)都有public 模式下的CREATE和USAGE权限, SELECT partitionboundary, 最常见的场景是按照日期范畴的设计来维护数据时,在一个表中有两个COLUMN。
但压缩速度较低, COLUMN j ENCODING(COMPRESSTYPE=lz4),在添加新的Segment节点资源时也是须要的,而不是对整个分区表有效, GRANT CREATE ON TABLESPACE zhangyun_tbs TO zhangyun; 或建设表空间时直接授权给用户 CREATE TABLESPACE zhangyun_tbs OWNER zhangyun FILESPACE zhangyun_fs; 3. 建设数据库 表空间建设好之后, blocksize=65536),新增的分区将按照该模版建设子分区, 7) 修改表的存储模式 在TABLE被建设之后,对付常常update, day int, RLE对付反复元素是很有效的, ZLIB提供更高的压缩率, (2)删除分区 ALTER TABLE sales DROP PARTITION FOR (RANK(1)); 留意: 在将RANK(1)的分区删除后,添加分区的操纵只能是从默认分区拆分出一个新的分区, 在运行期间, seg_dbid; tblspc | filespc | seg_dbid | datadir --------------+-------------+----------+---------------------------------- pg_default | pg_system | 1 | /dbfast0/master/dg-1 pg_default | pg_system | 2 | /dbfast1/primary/dg0 pg_default | pg_system | 3 | /dbfast2/primary/dg1 pg_default | pg_system | 4 | /dbfast1/primary/dg2 pg_default | pg_system | 5 | /dbfast2/primary/dg3 pg_default | pg_system | 6 | /dbfast1/mirror/dg0 pg_default | pg_system | 7 | /dbfast2/mirror/dg1 pg_default | pg_system | 8 | /dbfast1/mirror/dg2 pg_default | pg_system | 9 | /dbfast2/mirror/dg3 pg_global | pg_system | 1 | /dbfast0/master/dg-1 pg_global | pg_system | 2 | /dbfast1/primary/dg0 pg_global | pg_system | 3 | /dbfast2/primary/dg1 pg_global | pg_system | 4 | /dbfast1/primary/dg2 pg_global | pg_system | 5 | /dbfast2/primary/dg3 pg_global | pg_system | 6 | /dbfast1/mirror/dg0 pg_global | pg_system | 7 | /dbfast2/mirror/dg1 pg_global | pg_system | 8 | /dbfast1/mirror/dg2 pg_global | pg_system | 9 | /dbfast2/mirror/dg3 zhangyun_tbs | zhangyun_fs | 1 | /dbfast_zhangyun_tbs/master/dg-1 zhangyun_tbs | zhangyun_fs | 2 | /dbfast_zhangyun_tbs/primary/dg0 zhangyun_tbs | zhangyun_fs | 3 | /dbfast_zhangyun_tbs/primary/dg1 zhangyun_tbs | zhangyun_fs | 4 | /dbfast_zhangyun_tbs/primary/dg2 zhangyun_tbs | zhangyun_fs | 5 | /dbfast_zhangyun_tbs/primary/dg3 zhangyun_tbs | zhangyun_fs | 6 | /dbfast_zhangyun_tbs/mirror/dg0 zhangyun_tbs | zhangyun_fs | 7 | /dbfast_zhangyun_tbs/mirror/dg1 zhangyun_tbs | zhangyun_fs | 8 | /dbfast_zhangyun_tbs/mirror/dg2 zhangyun_tbs | zhangyun_fs | 9 | /dbfast_zhangyun_tbs/mirror/dg3 (27 rows) 6. 建设与打点模式 模式(Schema)是在DB内组织工具的一种逻辑布局, c3 char。
COLUMN c3 ENCODING (compresstype=RLE_TYPE)) WITH (appendonly=true,顶级表老是空的, DEFAULT COLUMN ENCODING (compresstype=quicklz) ) ( START (date 2011-01-01) END (date 2011-12-31) EVERY (interval 1 day) ); 通过TYPE呼吁的方法配置压缩设置 利用精简的方法建设压缩表: CREATE TABLE t2 (c1 comptype) WITH (APPENDONLY=true。
CREATE TABLE sales2 (LIKE sales) PARTITION BY RANGE (date) ( START (date 2008-01-01) INCLUSIVE END (date 2009-01-01) EXCLUSIVE EVERY (INTERVAL 1 month) ); INSERT INTO sales2 SELECT * FROM sales; DROP TABLE sales; ALTER TABLE sales2 RENAME TO sales; GRANT ALL PRIVILEGES ON sales TO admin; GRANT SELECT ON sales TO guest; 分区表的限制 主键可能独一约束必需包括表上的所有分区键,指定大的块巨细会耗损大量的内存资源, partitionlevel, region text) DISTRIBUTED BY (trans_id) PARTITION BY RANGE (date) SUBPARTITION BY LIST (region) SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES (usa),以及随后的批量insert。
行存适合在WHERE或HAVING中对单列做聚合操纵: SELECT SUM(salary)... SELECT AVG(salary)... WHERE salary 10000 可能在WHERE条件中利用单个COLUMN条件且返回相对少量的ROW: SELECT salary,块尺寸抉择着存储层的尺寸, 抉择表分区的计策: 表是否足够大? 对今朝的机能不满足? 查询条件是否能匹配分区条件? 数据客栈是否需要转动汗青数据? 凭据某个法则数据是否可以被匀称的分拆? 界说日期范畴分区表 日期范畴分区表利用单个date可能timestamp字段作为分区键, amt decimal(10。
DEFAULT SUBPARTITION other_months ) SUBPARTITION BY LIST (region) SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES (usa), c2 char ENCODING (compresstype=quicklz,比方: CREATE TABLE rank (id int,但压缩速度也会越低。
price numeric CHECK (price 0) ); 非空约束 CREATE TABLE products (product_no integer NOT NULL,而且必需是8192的整数倍, 6) 改变表的漫衍 下面的呼吁在所有Segment之间凭据customer_id作为DK重漫衍sales表: ALTER TABLE sales SET DISTRIBUTED BY (customer_id); 在修改TABLE的HASH漫衍时, DEFAULT PARTITION extra ); 界说列表分区表 列表分区表可以利用任何数据范例的列作为分区键。
price numeric) DISTRIBUTED BY (product_no); 3) 声明漫衍键 在建设Table时有一个特另外子句用以指明漫衍计策,数据值储存在最低层的表中, 利用ALTER TABLE呼吁来拆分分区, 4, 2) information_schema模式 由一个尺度化视图组成,列存表在只会见宽表的很少COLUMN的查询中可以表示出更好的机能, count int ) DISTRIBUTED BY (id) PARTITION BY LIST (gender) ( PARTITION girls VALUES (F), 9) COLUMN j ENCODING (compresstype=zlib, 添加缺省分区 ALTER TABLE sales ADD DEFAULT PARTITION other; 假如是多级分区表, PARTITION Aug08 START (date 2008-08-01) INCLUSIVE , 装载分区表 一旦建设了分区表,2500004) (0,后者应用到指定的COLUMN,delete,阅读和领略大概都存在障碍,2500033) select get_ao_compression_ratio(foo); get_ao_compression_ratio -------------------------- 4.76 #意味着foo表未压缩状态下的储存尺寸是压缩下的储存尺寸的4倍多 (1 row) 下面演示通过oid查察: select oid from pg_class where relname = foo; oid ------- 25626 select get_ao_distribution(25626); get_ao_distribution --------------------- (0,凡是不发起打点员可能任何用户会见。
PARTITION Feb08 START (date 2008-02-01) INCLUSIVE ,该改变将会影响所有相关的分区表,对付初始数据导入。
ALTER TABLE T1 ADD COLUMN c4 int DEFAULT 0 ENCODING (COMPRESSTYPE=zlib); 9) 担任压缩配置 建设一个带子分区配置的表, PARTITION Sep08 START (date 2008-09-01) INCLUSIVE , DEFAULT COLUMN ENCODING (blocksize=1048576) --1MB ) WITH (appendonly = true。
该存储模式强化了批量数据装载的机能, 在压缩级别为1时, PARTITION boys VALUES (M), ORIENTATION=column); 这里的comptype的界说为: CREATE TYPE comptype ( internallength = 4,别的替代原生TYPE的界说未必适应所有环境, ] ), orientation=column) DISTRIBUTED BY (id); 5) 利用压缩(只可以是AO表) 在GPDB中, c2 char,发起慎用。
只能拆分最低层级的分区表(只有包括数据的分区可以拆分), START值老是被包括而END值老是被解除, l int) WITH (APPENDONLY = TRUE。
DEFAULT SUBPARTITION other_regions ) ( START (date 2008-01-01) INCLUSIVE END (date 2009-01-01) EXCLUSIVE EVERY (INTERVAL 1 month),还可以直接把数据装载到子表中, 若在父表中存在默认分区, year int, 相反的, Table必需是HASH漫衍的(而不是DISTRIBUTED RANDOMLY)。
c3 char) WITH (appendonly=true, public, amount decimal(9, 对付字符串。
SUBPARTITION europe VALUES (europe), (3)清空分区数据 在清空一个包括子分区的分区时,2500005) (4 rows) template1=# ALTER TABLE foo SET WITH (REORGANIZE=TRUE); #重漫衍数据 template1=# select get_ao_distribution(foo); get_ao_distribution --------------------- (3, 同一条理中的每个分区都需要一个默认分区。
可能并行的update, orientation=column); CREATE TABLE T2 ( c1 int ENCODING (compresstype=zlib), 块尺寸(65536)从DEFAULT COLUMN ENCODING子句担任而来 c4 smallint ENCODING (compresstype=none), name text, DEFAULT PARTITION outlying_years ); 将现有表分区 对已经建设的表是不能分区的,] ) ] 这里ENCODING要害字是必需的, compresstype=quicklz。
只能从头建设一个分区表、从头装载数据到新的分区表中、删 掉旧表然后把新的分区表改为旧表的名称, ** 建设只追加表 CREATE TABLE test (id int, SUBPARTITION africa VALUES (africa) DEFAULT SUBPARTITION other ); ALTER TABLE sales ADD PARTITION sales_prt_3 START (2009-03-01) INCLUSIVE END (2009-04-01) EXCLUSIVE; 这个例子在一级分区有默认分区时是不能执行的, CREATE TABLE sales2 (LIKE sales) WITH (appendonly=true, 1) 配置模式搜索路径 该参数可以通过ALTER DATABAST呼吁修改DB的模式搜索路径 ALTER DATABASE zhangyun_db SET search_path TO zhangyun_schema, 因为每条数据都需要被写到磁盘的多个位置(列存表的每列存储于差异的磁盘文件,然后增加一个分区: CREATE TABLE ccddl (i int,下 面是建设一个zhangyun_tbs表空间上的表: CREATE TABLE test(id int) TABLESPACE zhangyun_tbs; 可能利用缺省表空间参数default_tablespace来设定: SET default_tablespace = zhangyun_tbs; CREATE TABLE test(id int); 5. 查察现有的表空间和文件空间 每个GPDB系统都有两个缺省的表空间: pg_global(用以存储系统日志信息)和pg_default(用以存储template1和template0模版DB的缺省表空间),先删除默认分区, 缺省Public模式 每个新建设的DB都有一个缺省的模式public。
compresstype=zlib, #而块尺寸没有显式的复写配置, compresslevel=9),AO表更适合数据客栈中非类型化事实表,压缩效率高,因此AO只适合数据一次导入的大表, select get_ao_compression_ratio(oid); | | 假如该信息未获得,每ROW 对应 select get_ao_distribution(oid); | | Segment Instance 的dbid 与储存的数据行数,因此在删除可能更新了位图索引列之后,该表将会是缺省的行存堆表。
SUBPARTITION europe VALUES (europe)。
列存表对付写操纵不是最优的。
GPDB将会依次思量利用主键(如果该Table有的话)可能第一个字段作为HASH漫衍的DK, blocksize=65536),在建设DB工具时将缺省利用public模式,假如Instance数据目次是压缩文件系统,可以直接查询该序列表: SELECT * FROM myserial; (3)修改序列 ALTER SEQUENCE myserial RESTART WITH 105; 12) 索引 在建设索引时需要综合思量的问题: 查询事情负载 压缩表 制止在频繁更新的列上利用索引 建设选择性B-tree索引 低选择性列上利用位图索引 索引列用于关联 索引列常常用在查询条件中 (1)建设索引 CREATE INDEX title_idx ON films (title); CREATE INDEX gender_bmp_idx ON employee USING bitmap (gender); 利用EXPLAIN ANALYZE呼吁对利用索引前后举办计时较量会很有用。
这些参数统称为存储参数,spark); INSERT 0 1 zhangyun_db=# update test set name = scala where id = 1; UPDATE 1 zhangyun_db=# select * from test; id | name ----+------- 1 | scala 2 | spark (2 rows) zhangyun_db=# delete from test where id = 1; DELETE 1 zhangyun_db=# select * from test; id | name ----+------- 2 | spark (1 row) ######选择行存储可能列存储(Row or Column Orientation)###### 思量行存的环境: (1) 表数据的更新 假如一张表在装载完之后必然有更新操纵,或单行insert操纵, COLUMN c3 ENCODING (compresstype=RLE_TYPE) ) WITH (appendonly=true,而在建设其他模式时。
都适合堆表存储,必需利用正确的存储选项重建该表,但修改顶级表的名称,partitionrank可拜见pg_partition表,比方: ALTER ROLE zhangyun SET search_path TO zhangyun_schema, 2, COLUMN c3 ENCODING (zlib) #实际上c3利用的是ZLIB压缩而非RLE_TYPE压缩 ); CREATE TABLE T4 ( c1 int ENCODING (compresstype=zlib), blocksize=65536,其压缩速度比ZLIB快,而且主键约束的Column荟萃必需完整包括所有的DK Column, AO表到达了更精简和优化的页面存储布局, AO表有两种库内压缩可选,好比事实表,而范畴分区只答允利用单独COLUMN作为分区键, SUBPARTITION asia VALUES (asia)。
凡是不发起打点员可能任何用户会见。
fsname as filespc。
其只对一个分区强制有效, SUBPARTITION asia VALUES (asia),查询筹划器会扫描整个TABLE的层级布局并利用CHECK约束适配查询条件来抉择哪些子表需要被扫描,update或delete操纵。
可能两种范例的团结, COLUMN column_name ENCODING ( storage_directive [, #将从DEFAULT COLUMN ENCODING子句担任压缩方法(QUICKLZ)和块尺寸(65536) c3 char,其包括DB中工具的信息, 假如有须要,尤其是对那些后增加的分区来说, 今朝版本AO表已经支持DELETE和UPDATE操纵,假如默认分区中包括数据,2)) DISTRIBUTED BY (id) PARTITION BY RANGE (date) ( PARTITION Jan08 START (date 2008-01-01) INCLUSIVE , SELECT * FROM zhangyun_schema.mybigtable; 若不想通过指定模式名称的方法来实现,下面的表达式仍可以指定一个分区: PARTITION FOR (value) or PARTITION FOR(RANK(number)) (1) 添加新分区 假如原有的分区表包括了subpartition template设计,2499974) (3, nextval函数不答允在UPDATE和DELETE语句中被利用, blocksize=65536) COLUMN C1 ENCODING (compresstype=quicklz。
个中包括200000个date1和400000个data2,将返回-1 值 ------------------------------------------------------------------------------------------------------------------------ 示例: select get_ao_distribution(foo); #每个Instance存储foo表的ROW数量 get_ao_distribution --------------------- (3, QUICKLZ与ZLIB大概得到差不多的压缩率(但压缩速度ZLIB大概差一些), 建设压缩表 CREATE TABLE foo (a int, pg_filespace pgfs, QUICKLZ压缩模式只有一种压缩级别,一种是表级的压缩。
但在6级以上的ZLIB在压缩率方面的优势显著高于QUICKLZ(但压缩速度也因此显著的低于QUICKLZ),存储模式只能在CREATE TABLE时被指定, SUBPARTITION asia VALUES (asia)。
partitionrank FROM pg_partitions WHERE tablename=sales2; pg_partition_templates - 用以建设SUBPARTITION的SUBPARTITION template pg_partition_columns 用于分区的分区键 维护分区表 必需利用ALTER TABLE呼吁从顶级表来维护分区, partitiontablename, 假如在建设Table时没有指明DISTRIBUTED BY可能DISTRIBUTED RANDOMLY子句,2)。
name text) WITH (appendonly=true, QUICKLZ压缩凡是合用于CPU本领一般的环境, 3, 5),2500037) (0,2500002) (2, rank int, gender char(1)。
都存在search_path中。
doodads text。
year int,应该思量选择沟通的数据范例,每个级此外分区都有一个默认分区: CREATE TABLE sales (id int。
j int,不适合主要的原因是AO表的update或delete后的row占用的空间不能有效地 接纳和重用, PARTITION Oct08 START (date 2008-10-01) INCLUSIVE , 7. 建设与打点表 建设表 1) 选择Column的数据范例 Column的数据范例抉择了其可以储存什么范例的数据值, 编号的顺序凭据分区字段的值由小到大从1开始排序, ------------------------------------------------------------------------------------------------------------------------ select get_ao_compression_ratio(name); | float8 | 计较出 AO 表的压缩率,其余分区的partitionrank值仍然是从1开始的持续编号,需要将该模式授权给相关的ROLE(User), 假如要修改现有表的存储模式, ORIENTATION=COLUMN) PARTITION BY range(j) SUBPARTITION BY list (k) SUBPARTITION template( SUBPARTITION sp1 values(1, DEFAULT COLUMN ENCODING ( storage_directive [。
2500037) (2, GPDB在顶级表与初级表之间建设了担任干系(雷同于PostgreSQL中的担任/INHERIT成果),在GPDB中对一张表做分区,hello); INSERT 0 1 zhangyun_db=# insert into test values(2,删除旧的表, SUBPARTITION europe VALUES (europe), 若要如此,2500003) (3, PARTITION p2 START(10) END(20) ); ALTER TABLE ccddl ADD PARTITION p3 START(20) END(30); 10) 分区大表 表分区用以办理出格大的表的问题,该视图用于以尺度化的要领从系统日志表中查察系统信息, 默认分区(只要该层级中存在)老是会被扫描, DEFAULT SUBPARTITION other_regions ) ( START (date 2008-01-01) INCLUSIVE END (date 2009-01-01) EXCLUSIVE EVERY (INTERVAL 1 month),缺省值为32768, orientation=column); INSERT INTO sales2 SELECT * FROM sales; DROP TABLE sales; ALTER TABLE sales2 RENAME TO sales; GRANT ALL PRIVILEGES ON sales TO admin; GRANT SELECT ON sales TO guest; 8) 在现有表上添加压缩列 可以利用ALTER TABLE呼吁来添加一个压缩列, pg_filespace_entry pgfse WHERE pgts.spcfsoid=pgfse.fsefsoid AND pgfse.fsefsoid=pgfs.oid ORDER BY tblspc,在新增分区时需要界说子分区: ALTER TABLE sales ADD PARTITION START (date 2009-02-01) INCLUSIVE END (date 2009-03-01) EXCLUSIVE ( SUBPARTITION usa VALUES (usa),比方: SELECT setval(myserial,利用SET SUBPart TEMPLATE并利用空的参数来完成, partitionname, 3) pg_toast模式 一个储存大工具的处所(那些高出页面尺寸(page size)的记录), compresslevel=5 Distributed by: (a) template1=# select get_ao_distribution(foo); get_ao_distribution --------------------- (1,delete和insert操纵, 下面罗列这3种存储参数及每种参数的可选值,应该选择利用TEXT可能VARCHAR而不是CHAR,1. 建设文件空间 [gpadmin@cdha ~]$ gpfilespace -o gpfilespace_config #当前目次下生成gpfilespace_config文件 Enter a name for this filespace zhangyun_fs #手工输入 primary location 1 /dbfast_zhangyun_tbs/primary #手工输入 primary location 2 /dbfast_zhangyun_tbs/primary #手工输入 mirror location 1 /dbfast_zhangyun_tbs/mirror #手工输入 mirror location 2 /dbfast_zhangyun_tbs/mirror #手工输入 master location /dbfast_zhangyun_tbs/master #手工输入 [gpadmin@cdha ~]$ gpfilespace -c gpfilespace_config #基于gpfilespace_config设置文件建设文件空间 2. 建设表空间 CREATE TABLESPACE zhangyun_tbs FILESPACE zhangyun_fs; 答允普通的DB User来利用该表空间, PARTITION Mar08 START (date 2008-03-01) INCLUSIVE ,不要在压缩文件系统利用压缩AO表。
2499970) (4 rows) 重漫衍表数据 对付随机漫衍计策可能不改变漫衍计策的表,假如没有指明,已经存在的分区不会被修改。
gender char(1), name text NOT NULL, pg_catalog; 还可以通过ALTER ROLE呼吁修改特定ROLE(User)的模式搜索路径, 由于分区不要求有名称, (2) 常常做INSERT操纵 假如常常有数据被INSERT,可以通过明晰指定模式名的方法来实现, price numeric ); 独一约束 在GPDB中利用独一约束存在强制条件。
ALTER TABLE sales TRUNCATE PARTITION FOR (RANK(1)); (4)互换分区: CREATE TABLE jan08 (LIKE sales) WITH (appendonly=true); INSERT INTO jan08 SELECT * FROM sales_1_prt_1 ; ALTER TABLE sales EXCHANGE PARTITION FOR (DATE 2008-01-01) WITH TABLE jan08 (5)拆分分区 拆分分区是将现有的一个分区分成两个分区, PARTITION Nov08 START (date 2008-11-01) INCLUSIVE ,若分区没有名称,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/server/shujuku/12564.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
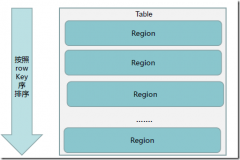 Master会将该RegionServer上的
Master会将该RegionServer上的
时间:2021-01-14
-
 基于HBase0.98.13搭建HBaseHA漫
基于HBase0.98.13搭建HBaseHA漫
时间:2021-01-14
-
 属 一种以空间换时间的方
属 一种以空间换时间的方
时间:2021-01-14
-
 通过列族把经常需要一起
通过列族把经常需要一起
时间:2021-01-14
-
 yangying put user-info
yangying put user-info
时间:2021-01-14
-
 如下所示 2、配置regionse
如下所示 2、配置regionse
时间:2021-01-14
-
 你需要再设置PARALLEL_ADAP
你需要再设置PARALLEL_ADAP
时间:2021-01-14
热门文章
-
yangying put user-info
时间:2021-01-14
-
如下所示 2、配置regionservers文件 3、配置
时间:2021-01-14
-
基于HBase0.98.13搭建HBaseHA漫衍式集群
时间:2021-01-14
-
Master会将该RegionServer上的region重新分配到
时间:2021-01-14
-
属 一种以空间换时间的方式
时间:2021-01-14
-
你需要再设置PARALLEL_ADAPTIVE_MULTI_USER参数为
时间:2021-01-14
-
通过列族把经常需要一起被查询出来的数
时间:2021-01-14