java_Java中实现双数组Trie树实例,传统的Trie实现简单,但是占用
{
for(int i=1;i<=CharMap.size();++i)
{
{
for(int i=0;i<r.size();++i)
import java.io.InputStream;
for(String word: words)
Pos = CopyToTailArray(s,i+1);
public class DoubleArrayTrie {
{
Base[avail_base+GetCharCode(Tail[head])] = 0;
CharMap.put(END_CHAR,1);
//更新新的cur_p
String prefix = "";
for(int j=0;j<set.length;++j)
//result.addAll(GetAllChildWord(Base[index]+i));
final char END_CHAR = '\0';
result.add(r);
{
Base[cur_p] = -Pos;
import java.util.Scanner; import java.util.ArrayList;
public boolean Exists(String word)
{
String s;
fs.p = cur_p;
//如果长度超过现有,拓展数组
* 2. Check[Base[cur_p] + Code('END_CHAR')] == cur_p
return true;
//获取状态位置
}
ArrayList<Integer> list1 = GetChildList(pre_p);
Base[avail_base+GetCharCode(s.charAt(i+1))] = 0;
CharList.add(c);
{
* Author: Yaguang Ding
DoubleArrayTrie dat = new DoubleArrayTrie();
System.out.println(dat.Exists(word));
pre_p = cur_p;
result.add("");
for(int i=0;i<word.length();++i)
{
}
}
* Date: 2012/5/21
Base[toBeAdjust] = avail_base;
}
int avail_base = x_check((Integer[])list.toArray(new Integer[list.size()]));
Pos = CopyToTailArray(s,i+1);
ArrayList<String> words = new ArrayList<String>();
//冲突 1:遇到 Base[cur_p]小于0的,即遇到一个被压缩存到Tail中的字符串
int origin_base = Base[toBeAdjust];
Tail[_Pos] = s.charAt(i);
}
int num = 0;
Base[1] = 1;
public void Insert(String s) throws Exception
else
}
{
}
Base[avail_base+GetCharCode(Tail[head])] = -(head+1);
//有后续
pre_p = cur_p;
s2 += END_CHAR;
{
}
FindStruct fs = Find(word);
}
所以在查询的时候要考虑一下这两种情况
r+= Tail[i];{
private int GetCharCode(char c)
char Tail[] = new char [DEFAULT_LEN];
双数组Trie就是优化了空间的Trie树,原理本文就不讲了,请参考An Efficient Implementation of Trie Structures,本程序的编写也是参考这篇论文的。
}elseelse
private FindStruct Find(String word)
if(s.charAt(i+1)== END_CHAR && Tail[head]==END_CHAR) //插入重复字符串
pre_p = cur_p;
}
list = list1;
return fs;
ret.add(i);
System.out.println(dat.Base.length);
flag = false;
Check[avail_base+GetCharCode(s.charAt(i+1))] = cur_p;
}
if(Base[cur_p] > 0 && Check[cur_p] == pre_p)
{
for(int i=0; i<s.length(); ++i)
{
if(Base[index] == 0)
if(true)
fs.p = -1;
我增长数组的时候是每次长度增加到2倍,初始1024
* 1. Base[cur_p] == pos ( pos<0 and Tail[-pos] == 'END_CHAR' )* Mail: [email protected]
Extend_Tail();
复制代码 代码如下:
{ArrayList<Integer> ret = new ArrayList<Integer>();
{
}
//Tail 为END_FLAG 的情况
for(int i=p; i<s.length();++i)
int avail_base ;
private int CopyToTailArray(String s,int p)
cur_p = Base[pre_p]+GetCharCode(word.charAt(i));
public DoubleArrayTrie()
}
for(int i=0;i<26;++i)
{
}
return false;
{
}
private boolean TailMatchString(int start,String s2)
{
{
if(Check[Base[cur_p]+GetCharCode(END_CHAR)] == cur_p)
import java.io.BufferedReader;
}
Check[cur_p] = pre_p;
avail_base = x_check(new Integer[]{GetCharCode(s.charAt(i+1)),GetCharCode(Tail[head])});
String r="";
if(Base[index] < 0)
Check[tmp2] = Check[tmp1];
{
if(Tail[head] == END_CHAR)
while(sc.hasNext())
if(s2.charAt(i) != Tail[i+start]) return false;
Tail = Arrays.copyOf(Tail, Tail.length*2);
//冲突2:当前结点已经被占用,需要调整pre的base
{
}
{
Base和Check数组的长度为131072
ArrayList<Integer> subsequence = GetChildList(tmp1);
int tmp1 = origin_base + list.get(j);
ArrayList<String> r = GetAllChildWord(p);
{
}
list.remove(list.size()-1);
cur_p = Base[pre_p]+GetCharCode(s.charAt(i));
private void Extend_Array()
}
if(Check[cur_p] != pre_p) return false;
return r;
}
传统的Trie实现简单,但是占用的空间实在是难以接受,特别是当字符集不仅限于英文26个字符的时候,爆炸起来的空间根本无法接受。
{}
Base[cur_p] = 0;
import java.io.InputStreamReader;
if(s.charAt(i+1) == END_CHAR)
String prefix="";
}
return fs;
{
}
return result;
{
else
}
continue;
if(Base[cur_p]!= 0 || Check[cur_p]!= 0)
{
final int DEFAULT_LEN = 1024;
}
String r="";
for(int j=0; j<list.size(); ++j)
private int x_check(Integer []set)
return CharMap.get(c);
{
if(s.charAt(i) == END_CHAR)
Base[cur_p] = avail_base;
int pre_p = 1;
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("E:/兔子的试验学习中心[课内]/ACM大赛/ACM第四届校赛/E命令提示/words3.dic")));
break;
else
if (flag) return i;
{
//已存在状态
Scanner sc = new Scanner(System.in);
int p = fs.p;
import java.io.IOException;
int pre_p = 1;
int cur_p = 0;
CharMap.put((char)('a'+i),CharMap.size()+1);
}
if(Base[p]+i >= Check.length) break;
复制代码 代码如下:
if(Check[cur_p] != pre_p)Check[avail_base+GetCharCode(s.charAt(i+1))] = cur_p;
return result;
import java.io.FileInputStream;
_Pos++;
return _Pos;
}
Base[tmp1] = 0;
int tmp2 = avail_base + list.get(j);
{
}
import javax.xml.crypto.Data;
for(int i=-Base[p];Tail[i]!=END_CHAR;++i)Map<Character ,Integer> CharMap = new HashMap<Character,Integer>();
{
if(Base[p] > 0)
}
{
int Pos = 1;
private ArrayList<Integer> GetChildList(int p)
return true;
}
}
{
return true;
continue;
}
{
for(int i=0;i<word.length();++i)
{
fs.p = -1;
for(int i=1; i<=CharMap.size();++i)
}
关于几点论文没有提及的细节和与论文不一一致的实现:
}1.对于插入字符串,如果有一个字符串是另一个字符串的子串的话,我是将结束符也作为一条边,产生一个新的结点,这个结点新节点的Base我置为0
/*
if(TailContainString(-Base[cur_p],word.substring(i+1)))
String word = sc.next();
Check[tmp1] = 0;
ArrayList<String> result = new ArrayList<String>();
break;
}
if(Base[tmp1] > 0)
}
if (Tail[head] == s.charAt(i+1))
Base[avail_base+GetCharCode(s.charAt(i+1))] = -(head+1);
}
words.add(s);
return result;
下面是java实现的代码,可以处理相同字符串插入,子串的插入等情况
Base[avail_base+GetCharCode(s.charAt(i+1))] = -Pos;
//公共字母的情况,因为上一个判断已经排除了结束符,所以一定是2个都不是结束符
{
int cur_p = 0;
if(Base[cur_p] < 0 && Check[cur_p] == pre_p)
public ArrayList<String> FindAllWords(String word)
for(int i=0;i<s2.length();++i)
fs.prefix += word.charAt(i);
int cur_p = i+set[j];
return result;
for(int i=1; ; ++i)
public class Main {
}
import java.util.Arrays; dat.Insert(word);
}
while(s.length()-p+1 > Tail.length-Pos)
break;
}else
2.对于第一种冲突(论文中的Case 3),可能要将Tail中的字符串取出一部分,作为边放到索引中。论文是使用将尾串左移的方式,我的方式直接修改Base值,而不是移动尾串。
CharMap.put(c,CharMap.size()+1);}
}
if(Base[cur_p] < 0)
{
CharList.add(END_CHAR);
for(int k=0; k<subsequence.size(); ++k)
* Name: Double Array Trie
Tail的长度为262144
if (cur_p >= Base.length) Extend_Array();Check = Arrays.copyOf(Check, Check.length*2);
} fs.p = cur_p;
ArrayList<Character> CharList = new ArrayList<Character>();
System.out.println(dat.Tail.length);
public ArrayList<String> GetAllChildWord(int index)
Base = Arrays.copyOf(Base, Base.length*2);
{
int cur_p;
{
{
{
Check[Base[tmp1]+subsequence.get(k)] = tmp2;
ArrayList<Integer> list = null;
int avail_base = x_check(new Integer[]{GetCharCode(s.charAt(i+1))});
CharList.add(END_CHAR);
}
{
list.add(GetCharCode(s.charAt(i)));
num ++;
import java.util.ArrayList;
r.set(i, fs.prefix+r.get(i));
cur_p = Base[pre_p]+GetCharCode(word.charAt(i));
result.add(CharList.get(i)+s);
if (p == -1) return result;
//2个字母不相同的情况,可能有一个为结束符
}
*/
if(Base[p]<0)
for(int i=-Base[index];Tail[i]!=END_CHAR;++i)
{
return false;
Base[tmp2] = Base[tmp1];
return ret;
{
int toBeAdjust;
}
CharList.add((char)('a'+i));
private void Extend_Tail()
{
{
if (!CharMap.containsKey(c))
}else
下面是测试结果,构造6W英文单词的DAT,大概需要20秒
}所以一个字符串结束也有2中情况:一个是Base值为负,存储剩余字符(可能只有一个结束符)到Tail数组;另一个是Base为0。
* Note: a word ends may be either of these two case:boolean flag = true;
int p;
{
System.out.println(dat.FindAllWords(word));
{
pre_p = cur_p;
//空闲状态
int Base[] = new int [DEFAULT_LEN];
}
Base[cur_p] = -Pos;
if(Check[Base[p]+i] == p)
if(Check[cur_p] != pre_p)
}
import java.util.Map;
* Blog: blog.csdn.net/dingyaguang117
}
break;
Base[cur_p] = avail_base;
}
}
}
测试代码:
return fs;
import java.util.HashMap;
ArrayList<String> result = new ArrayList<String>();
int pre_p = 1;
}
toBeAdjust = pre_p;
Check[cur_p] = pre_p;
}
//内部函数,返回匹配单词的最靠后的Base index,
int Check[] = new int [DEFAULT_LEN];
{
{
int _Pos = Pos;
if(cur_p>= Base.length) Extend_Array();
{
}
FindStruct fs = new FindStruct();
if(Base[cur_p] < 0)
return fs;
Pos = CopyToTailArray(s,i+2);
if(s2.charAt(i) != Tail[i+start]) return false;
{
}
{
s += END_CHAR;
for(int i=0;i<s2.length();++i)
Check[avail_base+GetCharCode(Tail[head])] = cur_p;
if(Base[cur_p] == 0 && Check[cur_p] == 0)
break;
return result;
result.add(fs.prefix+r);
cur_p = Base[pre_p]+GetCharCode(s.charAt(i));
while((s=reader.readLine()) != null)
return true;
{
public static void main(String[] args) throws Exception {
// BUG
{
{
for(String s:GetAllChildWord(Base[index]+i))
class FindStruct
r+= Tail[i];
}
{
相关热词: 实例
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/jiaob/java/5676.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 Fitness fitness){ /*double X1=m
Fitness fitness){ /*double X1=m
时间:2021-01-21
-
 所以这里也是需要注意的
所以这里也是需要注意的
时间:2021-01-21
-
 hadoop上传文件成果实例代
hadoop上传文件成果实例代
时间:2021-01-15
-
 hadoop负责按key值将map的输
hadoop负责按key值将map的输
时间:2021-01-15
-
 记得勾选springconfig.xml 因为
记得勾选springconfig.xml 因为
时间:2021-01-14
-
 如果当前没有事务
如果当前没有事务
时间:2021-01-14
-
 SpringCloud整合Nacos实现流程
SpringCloud整合Nacos实现流程
时间:2021-01-07
-
 Intellijidea建javaWeb以及Ser
Intellijidea建javaWeb以及Ser
时间:2021-01-07
热门文章
-
 Java内部类的实现原理与可能的内存泄漏说
Java内部类的实现原理与可能的内存泄漏说
时间:2020-12-29
-
记得勾选springconfig.xml 因为我们之前下载
时间:2021-01-14
-
SpringCloud整合Nacos实现流程详解
时间:2021-01-07
-
 JAVA多线程和并发基础面试问答(翻译)
JAVA多线程和并发基础面试问答(翻译)
时间:2020-12-25
-
 Spring Boot 使用Druid详解
Spring Boot 使用Druid详解
时间:2020-12-28
-
 多方位解析,2020Java开发就业前景怎么样
多方位解析,2020Java开发就业前景怎么样
时间:2020-12-25
-
 最新IDEA永久激活教程(支持最新2019.2版本
最新IDEA永久激活教程(支持最新2019.2版本
时间:2020-12-25
-
Fitness fitness){ /*double X1=min+0.382*(max-min);*
时间:2021-01-21
-
 详解SpringMVC在IDEA中的第一个程序
详解SpringMVC在IDEA中的第一个程序
时间:2021-01-06
-
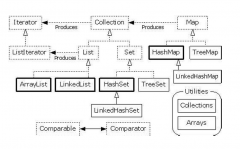 Java基础:集合框架
Java基础:集合框架
时间:2020-12-28