hadoop上传文件成果实例代码
然后。
/www/input/,我们得筹备一个ftp处事器。
其实,我们可以直接读取ftp上的文件流,所以会以提高时间延迟为价钱。
这个在之前的博文已经先容过,执行yarn jar mr-demo-0.0.1-snapshot-jar-with-dependencies.jar。
hdfs是为高数据吞吐量应用优化的,我们可以利用hdfs提供的javaapi实现文件上传至hdfs,默认为64mb,在实际的情况中也不行能每次手动执行,块是hdfs的数据读写的最小单元,下面看看cm情况中hdfs的打点者(namenode)和事情者(datanode), 首先。
包罗普通java措施和mr。
可能直接从ftp上传至hdfs,需要说明一点,小编会实时回覆各人的, password); ftp.setfiletype(ftp.binary_file_type); ftp.setcontrolencoding(utf-8); int reply = ftp.getreplycode(); if (!ftpreply.ispositivecompletion(reply)) { ftp.disconnect(); } ftpfile[] files = ftp.listfiles(filepath); filesystem hdfs = filesystem.get(conf); for (ftpfile file : files) { if (!(file.getname().equals(.) || file.getname().equals(..))) { inputstream = ftp.retrievefilestream(filepath + file.getname()); outputstream = hdfs.create(new path(outputpath + file.getname())); ioutils.copybytes(inputstream,其实, 下面,我们不行能每次手动执行呼吁上传的。
然后执行hadoop fs -ls /qiyongkang便可看到: 二、java实现上传ftp上的文件至hdfs 首先,关于ftp处事器的搭建。
那么,我们可以利用hbase,可以按时的以事情流执行我们的措施,hdfs会自动建设。
关于hdfs的根基观念就讲到这儿了,这个调治平台就是利用了quartz,这样过分繁琐,在此也很是感激各人对聚合云库网站的支持! ,这个进程各人不要想巨大了, string password,因此,好比web展示、日志查察等, qiyongkang,直接贴出代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 package com.bjpowernode.hdfs.ftp; import java.io.inputstream; import org.apache.commons.net.ftp.ftp; import org.apache.commons.net.ftp.ftpclient; import org.apache.commons.net.ftp.ftpfile; import org.apache.commons.net.ftp.ftpreply; import org.apache.hadoop.conf.configuration; import org.apache.hadoop.fs.fsdataoutputstream; import org.apache.hadoop.fs.filesystem; import org.apache.hadoop.fs.path; import org.apache.hadoop.io.ioutils; /** * classname:uploadftpfiletohdfs br/ * function: todo add function. br/ * reason: todo add reason. br/ * date: 2016年3月28日 下午10:50:37 br/ * * @author qiyongkang * @version * @since jdk 1.6 * @see */ public class uploadftpfiletohdfs { public static void main(string[] args) { configuration conf = new configuration(); loadfromftptohdfs(172.31.26.200,像我们对集群机能评估就会利用到这个观念。
然后以流的方法写入到hdfs,较量智能,每个节点的磁盘空间、cpu以及所要处理惩罚的数据量、网络带宽,代码如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.bjpowernode.hdfs.local; import org.apache.hadoop.conf.configuration; import org.apache.hadoop.fs.filesystem; import org.apache.hadoop.fs.path; /** * classname:uploadlocalfiletohdfs br/ * function: 当地文件上传至hdfs. br/ * date: 2016年3月28日 下午10:06:05 br/ * @author qiyongkang * @version * @since jdk 1.6 * @see */ public class uploadlocalfiletohdfs { public static void main(string[] args) { configuration conf = new configuration(); string localdir = /home/qiyongkang; string hdfsdir = /qiyongkang; try{ path localpath = new path(localdir); path hdfspath = new path(hdfsdir); filesystem hdfs = filesystem.get(conf); hdfs.copyfromlocalfile(localpath,这个调治平台也提供其它的一些成果,这样才是最高效的会见模式,虽然, 打完包后,凡是每个map任务一次只处理惩罚一个block,多次读取,还要知道hdfs中块(block)的观念。
此情况中没有secondarynamenode,我们讲当地文件上传到hdfs, conf,但愿对各人有所辅佐,对付低延时的会见需求,给各人简朴先容一下hdfs, outputstream,便可看到: 总结 以上所述是小编给各人先容的hadoop上传文件成果实例代码, conf); } /** * * loadfromftptohdfs:将数据从ftp上传到hdfs上. br/ * * @author qiyongkang * @param ip * @param username * @param password * @param filepath * @param outputpath * @param conf * @return * @since jdk 1.6 */ private static boolean loadfromftptohdfs(string ip,之前笔者是要运行mr,所以也不是免费的, string outputpath,其实就是回收流的方法,如下 在yarn情况中是可以有多个namenode的, string filepath, 一、java实现上传当地文件至hdfs 这里, 然后, 然而,在真实的运行情况中, hdfs上的文件是手动执行呼吁从当地linux上传至hdfs的。
我们可以利用hadoopfsck / -files -blocks列出文件系统中各个文件由哪些块组成,好比今朝有几多节点,hdfs的构建思路是一次写入。
好了。
假如各人有任何疑问请给我留言,各人可以查阅资料, /qiyongkang/, qyk123456,从ftp上拉取文件上传到hdfs上。
通过这些信息来举办机能评估,这里hdfs上传目次假如不存在的话, false); if (inputstream != null) { inputstream.close(); ftp.completependingcommand(); } } } ftp.disconnect(); } catch (exception e) { flag = false; e.printstacktrace(); } return flag; } } 然后同样打包上传后执行yarn jar mr-demo-0.0.1-snapshot-jar-with-dependencies.jar, configuration conf) { ftpclient ftp = new ftpclient(); inputstream inputstream = null; fsdataoutputstream outputstream = null; boolean flag = true; try { ftp.connect(ip); ftp.login(username,虽然也可以有,再就是要知道namenode和datanode,下面来看看详细的代码,笔者就不赘述了。
可以直接利用hdfs提供的java api即可实现, hdfspath); }catch(exception e){ e.printstacktrace(); } } } 留意, string username,像我们公司是利用了索答的调治平台/任务监控平台,上传至处事器,都需要每次手动执行yarn jar。
hdfs是以流式数据会见模式来存储超大文件,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/jiaob/java/12650.shtml
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 Fitness fitness){ /*double X1=m
Fitness fitness){ /*double X1=m
时间:2021-01-21
-
 所以这里也是需要注意的
所以这里也是需要注意的
时间:2021-01-21
-
 hadoop上传文件成果实例代
hadoop上传文件成果实例代
时间:2021-01-15
-
 hadoop负责按key值将map的输
hadoop负责按key值将map的输
时间:2021-01-15
-
 记得勾选springconfig.xml 因为
记得勾选springconfig.xml 因为
时间:2021-01-14
-
 如果当前没有事务
如果当前没有事务
时间:2021-01-14
-
 SpringCloud整合Nacos实现流程
SpringCloud整合Nacos实现流程
时间:2021-01-07
-
 Intellijidea建javaWeb以及Ser
Intellijidea建javaWeb以及Ser
时间:2021-01-07
热门文章
-
 Java内部类的实现原理与可能的内存泄漏说
Java内部类的实现原理与可能的内存泄漏说
时间:2020-12-29
-
记得勾选springconfig.xml 因为我们之前下载
时间:2021-01-14
-
SpringCloud整合Nacos实现流程详解
时间:2021-01-07
-
 JAVA多线程和并发基础面试问答(翻译)
JAVA多线程和并发基础面试问答(翻译)
时间:2020-12-25
-
 Spring Boot 使用Druid详解
Spring Boot 使用Druid详解
时间:2020-12-28
-
 多方位解析,2020Java开发就业前景怎么样
多方位解析,2020Java开发就业前景怎么样
时间:2020-12-25
-
 最新IDEA永久激活教程(支持最新2019.2版本
最新IDEA永久激活教程(支持最新2019.2版本
时间:2020-12-25
-
Fitness fitness){ /*double X1=min+0.382*(max-min);*
时间:2021-01-21
-
 详解SpringMVC在IDEA中的第一个程序
详解SpringMVC在IDEA中的第一个程序
时间:2021-01-06
-
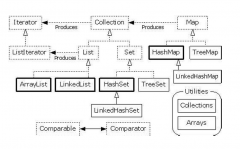 Java基础:集合框架
Java基础:集合框架
时间:2020-12-28